
The handling of Chinese characters [TN1] on computers is an important problem that cannot be avoided in the Chinese character cultural sphere of Asia.
Chinese characters were invented in China around 1300 B.C., and they spread together with politics, religion, and learning into the various nations of Asia, where they went on to variously fix themselves while merging with the cultures of those nations. Chinese characters were transmitted to Japan around 100 A.D. After that, people not only read Chinese characters and Classical Chinese in Japan, but a method called "manyoogana," which utilizes Chinese characters to express Japanese in writing, was invented. These manyoogana formed a nucleus, and then in the ninth century "hiragana" and "katakana" were born. Thereafter, Japanese has been flexibly expressed in writing up to the present by mixing hiragana, katakana, and kanji [Chinese characters]. Also, looking at just kanji, many kokuji [Note 1] and variants, which are deeply rooted in personal names, places names, and regional culture, came into existence and spread.
However, entering the 1970s, when Japanese came to be handled on computers, conversely with the abundant expressions of the Japanese language used in daily life, the sorts of kanji that could be used on computers ended up becoming limited due to such things as the processing power of computers. The after-effect of this continues up to the present, in which the performance of computers has improved.
In this article, we will first explain the problem points concerning the handling of Chinese characters on computers, and then, concerning TRON Code, which is a character code system aimed at their solution, we will elucidate its thinking and its detailed specification. Furthermore, we will also introduce an actual programming example in which TRON Code is handled.
Not just with characters or kanji, but also in a case where you intend to handle something such as some sort of concepts or images on a computer, if those are things that can precisely distinguished, then it is sufficient to just assign appropriate code numbers in an order. In fact, high-level processing can be realized by combining the Arabic numerals 0-9 and the 26 letters of the alphabet [Note 2].
However, in a case where one decides to express kanji on a computer, there occur problems such as the characters that one could express the way one wants with pencil and paper cannot be displayed, or the character shapes of the kanji that are actually displayed end up different from the design one is usually used to using.
If, from the beginning, the types of necessary kanji are clear, and, moreover, if a standard for distinguishing kanji that are regarded as the same and kanji that are regarded as different is clear, then it should be fine if we just assign codes in an order to the necessary kanji in accordance with those standards.
However, a lot of factors, such as the processing power of and demands on computers in the respective ages, the standardization trends of various character codes, and cultural and political backgrounds have combined, so these standards are always moving around, and they still show no signs of resolution.
First, let's take a look at the types of necessary Chinese characters. Table 1 is where we have collected together the numbers of kanji being used in Japan from the viewpoints of law and dictionaries.
|
|
||
| Jooyoo kanji-hyoo [Jooyoo (daily use) kanji table] | 1,945 characters |
|
| Kyooiku kanji [Education kanji] | 1,006 characters | Kanji to be learned in primary school from among the Jooyoo kanji |
| Hyoogai kanji jitai-hyoo [Table external (unlisted) kanji character form table] [Hereafter, 'Hyoogaiji'] | 1,022 characters |
|
| Jinmeiyoo kanji [Kanji for personal name use] | 983 characters |
|
| Tooyoo kanji-hyoo [Tooyoo kanji table] | 1,850 characters |
|
The Jooyoo kanji table, in the manner that it shows 1,945 characters as a yardstick for kanji use in the case of expressing the modern national language in general social life, is made up of approximately 2,000 general-use kanji that are used in daily life.
However, as shown in Table 2, the numbers of characters compiled in character dictionaries that are in circulation in Japan and China are from 10,000 to 86,000. This is because many Chinese characters that are not used at present and different variations of character variants are also recorded. Furthermore, as to the Chinese characters used in proper nouns, such as personal names and place names, there are ones that originate in each region's history and culture, and there are also examples of such things as something that was originally used as an erroneous character or popular character becoming fixed; moreover, a large number of Chinese characters that have not been recorded in Chinese character dictionaries have also been reported.
|
||
| Kadokawa Shin Jigen [Kadokawa new character source] | approx. 10,000 characters |
|
| Iwanami Shin Kango Jiten [Iwanami New Chinese word dictionary] | approx. 12,000 characters |
|
| Shin Kangorin [New Chinese word forest] | approx. 14,000 characters |
|
| Dai Kan-Wa Jiten [Great Chinese-Japanese Character Dictionary] | approx. 51,000 characters |
|
| Kangxi Zidian [K'ang-hsi dictionary] | approx. 49,000 characters | Chinese hanzi dictionary based on an imperial commission of Ch'ing Emperor K'ang-hsi; it had a great influence on character dictionaries created afterwards |
| Xinhua Zidian [New China character dictionary] | approx. 10,000 characters | Hanzi dictionary that is popular in present day China; now in 10th edition |
| Hanyu Da Zidian [Chinese language great character dictionary] | approx. 56,000 characters | Hubei dictionary, Sichuan dictionary; Chinese hanzi dictionary made up from a total of eight volumes |
| Zhonghua Zihai [China character ocean] | approx. 86,000 characters | Chung Hwa Book Co.; largest hanzi dictionary in China |
In other words, in accurately expressing on a computer Chinese characters used as proper nouns in such things as personal names and place names, or Chinese characters recorded in classical works and historical materials, there is the need to arrange and encode an enormous number of Chinese characters.
In order to make it so we can somehow standardize and handle on a computer an enormous number of Chinese characters in this manner, multiple character code systems have been devised in accordance with the cultural backgrounds and uses in the various countries. When we look at Table 3, we realize that the numbers of Chinese characters that can be expressed on computers are extremely limited.
|
| JIS X 0208:1997 6,355 characters |
Level 1 records 2,965 characters, and Level 2 3,390 characters; instituted in 1978 as JIS C 6226 (nicknames: 78JIS, old JIS); revised in 1983 (nicknames: 83JIS, new JIS), 1990, and 1997; because the replacement of character forms carried out in the revision of 1983 were incompatible changes, they invited confusion |
| JIS X 0212 5,801 characters |
Instituted in 1990; characters not included in JIS X 0208:1983 are collected together here; used together with JIS X 0208 |
| JIS X 0213:2000 10,040 characters |
Includes JIS X 0208; adds a total of 3,685 characters, with 1,249 characters in Level 3 and 2,436 characters in Level 4; nickname: JIS2000 |
| JIS X 0213:2004 10,050 characters |
To make the JIS standard agree with the "Hyoogaiji" inquiry, the illustrated character forms of JIS X 0213:2000 were modified, and 10 characters were added to Level 3; nickname: JIS2004 |
| GB 2312 6,763 characters |
National standard for simplified Chinese language characters instituted in 1980; level one records 3,755 characters, and level two records 3,008 characters |
| GB 18030 27,484 characters |
Higher level standard compatible with GB2312, which was instituted in 2000; can express the complete range of Unicode code positions |
| KS X 1001 4,888 characters |
Standard for expressing hangul and hanja in Korea; former KS C 5601 |
| Big5 13,060 characters |
Instituted by Taiwan's Institute for Information Industry in 1984; most generally used character set in the Chinese language traditional character sphere |
| CNS 11643 13,060 characters |
Taiwan national standard instituted in 1986; has not spread into general use |
| Note: Non-Chinese characters (kana, symbols, hangul, etc.) are not included in the above numbers of recorded Chinese characters. For example, the total number of characters in JIS X 0208 is 6,879; the number of kanji characters only is 6,355 shown above. |
In the Japanese JIS standards, the authors specify as a "unification rule" a range of "swaying" in which one can recognize the same kanji at one character code (row and cell [kuten] location) in regard to a kanji character form. Table 4 is where we give examples of the unification rule. The kanji to which this unification rule have been applied end up being assigned to one character code, even though they are normally expressed by distinguishing them printed materials, such as books and dictionaries. Even the Dai Kan-Wa Jiten introduced in Table 2, which is in general use in Japan, cannot be properly reproduced as is on a computer.
|
|
|
Revision of standard has been carried out several times up to the present for JIS X 0208 and JIS X 0213. At these times, because they have not only added characters to new character codes, but have also ended up carrying out modifications of the illustrated character shapes and replacement of characters, in spite of the fact that computers that adopted the old standard and computers that adopted the new standard are indicating the same character code, it comes about that a problem occurs in which kanji with different character shapes are displayed.
The greatest problem at the time there was a revision from JIS X 0213:2000 (hereafter JIS2000) to JIS X 0213:2004 (hereafter JIS2004) also lies in the fact that the illustrated character shapes were modified after partially revising the unification rule from JIS X 0208 in accordance with "Hyoogaiji." The character shape modifications have been made to be within the scope of the unification rule and design differences, but, depending on the environment used, there is no change in that kanji with a different character shapes from the character shapes the user intended end up being displayed.
Moreover, 10 characters to which the unification rule has been applied up to now were made "UCS-compatible table external kanji," and they were assigned new codes in order to provide compatibility between Hyoogaiji and Unicode (Table 5).
|
|
|
|
This kind of inconsistent revision of standards gave a shock to society.
The influence on customer databases and systems for business
use is enormous. This is because there is the possibility that
the written expressions of names and addresses registered in databases
will end up being changed. When you adopt a JIS2004-based font
in a system that distinguished between and used the JIS2000 illustrated
character shape ![]() and
and
![]() registered in the
user defined characters, because either of these codes both end
up being displayed with
registered in the
user defined characters, because either of these codes both end
up being displayed with ![]() ,
one must modify the system and create measures so that
,
one must modify the system and create measures so that ![]() can be displayed through something such as switching between the
user defined characters and the fonts. That smooth switching from
JIS2000 to JIS2004 is difficult has become one reason that migration
to Windows Vista, which adopted JIS2004, is not moving forward
in enterprises and government administrative offices.
can be displayed through something such as switching between the
user defined characters and the fonts. That smooth switching from
JIS2000 to JIS2004 is difficult has become one reason that migration
to Windows Vista, which adopted JIS2004, is not moving forward
in enterprises and government administrative offices.
The relationship between ![]() and
and ![]() has also become
a topic of discussion. Because Tokyo's Katsushika
Ward [TN2] adopted the
character
has also become
a topic of discussion. Because Tokyo's Katsushika
Ward [TN2] adopted the
character ![]() for
the official ward name, they were unable to display the ward name
as is on conventional computer systems, but it has become possible
to properly display it in JIS2004 environments. Conversely, Katsuragi City in
Nara Prefecture adopted
for
the official ward name, they were unable to display the ward name
as is on conventional computer systems, but it has become possible
to properly display it in JIS2004 environments. Conversely, Katsuragi City in
Nara Prefecture adopted ![]() as "a character shape utilized in computers," but because
this character was revised in JIS2004 after officials decided
on the name of the city, it has ended up coming about that one
cannot properly display the name of the city in new environments.
as "a character shape utilized in computers," but because
this character was revised in JIS2004 after officials decided
on the name of the city, it has ended up coming about that one
cannot properly display the name of the city in new environments.
At present in April 2009, the creation of a "Shin jooyoo kanji-hyoo [New daily use kanji table] (provisional name)" to replace the traditional Jooyoo kanji-hyoo is under study; its future trends, such as influences exerted on character codes, will draw attention.
As a method of expressing kanji that cannot be handled with existing character codes, gaiji [TN3], by which the user creates original characters and registers them in the undefined regions of a character code, are widely used.
Whether the user registers beforehand gaiji that a computer maker independently developed (system gaiji), or the user individually creates his own gaiji (user gaiji), by utilizing something such as a gaiji font in which one has collected together in the gaiji region kanji that are used in personal names and place names, people have made it so that they can express the necessary kanji. In publishing companies, there are even cases were an enormous number of gaiji are necessary in keeping with the printed material.
The problem point with gaiji is that you cannot properly display those characters outside of the computer on which the gaiji have been registered. In the case of an environment that uses many gaiji, system migration becomes difficult, because there are occasions on which data created up to that point become impossible to utilize when the environment changes.
Using Japanese domestic standards as an example, because one character code basically cannot be used in parallel with another character code [Note 3], there is also the problem that one cannot write Japanese and Chinese, for example, side by side.
Accordingly, in order to make it so that all the characters used in the world can be handled with a single character code, the standard called Unicode came into being (Table 6). In the latest version, Unicode 5.1, approximately 240,000 characters have been encoded, including approximately 71,000 Chinese characters.
|
||
| Unicode | approx. 71,000 | Character code proposed for the purpose of handling with a single character code the characters of multiple languages; latest version 5.1 |
| ISO/IEC 10646 | approx. 70,000 | International coded character set standard; unified with Unicode in 1993 |
| JIS X 0221 | approx. 70,000 | Standard to match the international ISO/IEC 10646 |
If there are as many as 71,000 characters just for Chinese characters, one might think that Unicode covers almost all the the Chinese characters that are being used in the world.
However, Unicode does not include the character codes of each
country as is, rather, based on a policy of "as far as possible
assigning to the same encoding location characters that possess
the same meaning or purpose," it has adopted a method in
which it independently assigns Chinese characters used in various
countries to one character code as a "unified CJK Chinese
character." For that reason, even if one would like to distinguish
as separate characters and deal with the Chinese characters of
Japan and the Chinese characters of China, distinguishing between
both becomes difficult when you use Unicode. For example, Japanese
![]() and Chinese
and Chinese ![]() , or Japanese
, or Japanese ![]() and Chinese
and Chinese ![]() are assigned to
the same code, and thus they cannot be distinguished as character
codes.
are assigned to
the same code, and thus they cannot be distinguished as character
codes.
On the other hand, Unicode has adopted a policy in which Chinese characters that are handled by distinguishing among several sources are not unified, even though they are Chinese characters that are similar in their character shapes (source separation Chinese characters). In a case where kanji sets that are subject to unification in the Japanese JIS standard are assigned separate codes in, for example, the standards of China and Taiwan, in Unicode also codes are assigned separately (Table 7).
|
|||
|
Furthermore, in Unicode3.0, CJK unified Chinese character extension A (4,542 characters), and in Unicode3.1, CJK unified Chinese character extension B (42,711 characters) were added, but the present state of affairs is that many kanji one would like to use through the distinguishing of character codes in Japan, such as variants of personal names and place names, have yet to be compiled.
That multiple character codes have been prepared for the purpose of expressing Chinese characters on a computer is understood, but the correspondence relationships of the characters among different character codes does not make for a complete one-to-one. As we have seen up to here, this is because various character codes arrange and classify Chinese characters with original standards, and then assign codes to them.
 |
|
|
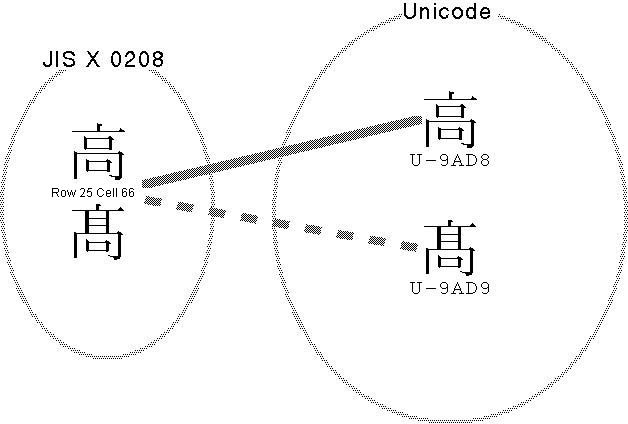
Let's take ![]() of
Table 7 in the previous section as an example and consider a case
where correspondence relationships of characters among the different
character codes becomes one-to-many (Fig. 1).
of
Table 7 in the previous section as an example and consider a case
where correspondence relationships of characters among the different
character codes becomes one-to-many (Fig. 1). ![]() of JIS X 0213's plane 1, row 25, cell 66 has been made to correspond
with Unicode's U + 9AD8; even with an actual character code conversion
program, normally conversion processing is carried out in this
manner. In Unicode,
of JIS X 0213's plane 1, row 25, cell 66 has been made to correspond
with Unicode's U + 9AD8; even with an actual character code conversion
program, normally conversion processing is carried out in this
manner. In Unicode, ![]() (nicknamed "hashigo [ladder] taka") exists
at U + 9AD9, but because
(nicknamed "hashigo [ladder] taka") exists
at U + 9AD9, but because ![]() and
and ![]() are unified and
are not distinguished in JIS, there will probably also be cases
where one would like to make JIS' plane 1, row 25, cell 66 correspond
with
are unified and
are not distinguished in JIS, there will probably also be cases
where one would like to make JIS' plane 1, row 25, cell 66 correspond
with ![]() of U + 9AD9. Conversely,
in a case where one converts from Unicode into JIS, even though
of U + 9AD9. Conversely,
in a case where one converts from Unicode into JIS, even though
![]() and
and ![]() are distinguished and expressed on the Unicode side, because it
is made up so that either one will be expressed with plane 1,
row 25, cell 66 in JIS, information concerning the distinction
between the two will be lacking after conversion, and it will
end up coming about that the distinguishing of
are distinguished and expressed on the Unicode side, because it
is made up so that either one will be expressed with plane 1,
row 25, cell 66 in JIS, information concerning the distinction
between the two will be lacking after conversion, and it will
end up coming about that the distinguishing of ![]() and
and ![]() won't be settled
with character codes alone.
won't be settled
with character codes alone.
Moreover, in a case where one will make correspondences among character codes that have large numbers of recorded characters, because the standards for arranging and classifying Chinese characters become more complex, cases where it becomes many-to-many can also be conceived. Considering the possibility of errors occurring in correspondence relationships of characters, it is necessary to cautiously carry out data conversion among different character codes. What aims at eliminating errors based on these types of character code conversions and leaving the original data in its original state is TRON Code.
The Merits of TRON Code
In the TRON Project, we have continued to research such things as operating system specifications for computers, data formats, and character code systems from the very start of the project around the middle of the 1980s. In particular, in regard to character code systems, we have pursued the ideal based on the realization that a framework compatible with an international multilingual system is necessary.
First, we stressed the following two points as the concrete policies of the TRON Code specification.
(1) No limits will be set on the number of characters that can be mixed together and handled simultaneously (2) It will be possible to mix together and handle simultaneously characters included in multiple character code sources
As previously mentioned, in order to accurately express the kanji recorded in a large-scale dictionary, such as the Dai Kan-Wa Jiten, or the kanji used in personal names, because one must at least distinguish among and handle characters that greatly exceed 100,000, two bytes are insufficient. Having said that, when you make it a character code of four bytes in length, code efficiency ends up becoming extremely bad when handling only alphanumeric data. For that reason, in TRON Code, we have adopted a method in which specify characters by means of switching via escape codes through assemblages of characters (called language planes or scripts) that are divided into 48,400 characters at a maximum.
TRON Code has been adopted by the BTRON-specification operating system, and, at present, it is implemented in the "Cho Kanji" series that is being marketed from Personal Media Corporation. In the latest version, Cho Kanji V, it is possible to distinguish among and express more than 180,000 characters (Table 8). TRON Code takes in existing multiple character code sources and character collections as is as individual character sets, and it is made up so that one can freely mix and handle all the characters by means of assigning codes to them respectively.
|
|
||
| Character Set/Script Name | No. of Characters | No. of Fonts |
| JIS Level 1 and Level 2 (JIS X 0208) |
6,879 |
4 |
| JIS Level 3 and Level 4 (JIS X 0213; JIS X 0213:2000 compatible) |
4,344 |
1 |
| JIS Auxiliary Kanji (JIS X 0212) |
6,067 |
2 |
| Korean hanja, hangul (KS X 1001) |
8,224 |
6 |
| Chinese basic (simplified GB 2312) |
7,445 |
4 |
| Chinese extended (simplified characters) |
634 |
1 |
| Chinese traditional characters (CNS 11643) |
13,491 |
2 |
| 6-point Braille, 8-point Braille |
320 |
1 |
| i-mode picture characters |
271 |
1 |
| GT Typeface Font |
78,675 |
1 |
| Dai Kan-Wa Jiten collected characters |
51,053 |
1 |
| Tompa (Dongba) characters |
1,362 |
1 |
| Hentaigana |
545 |
1 |
| Unicode Ver. 2.0 (a portion of the non-Chinese character characters) | ||
| Latin characters |
865 |
2 |
| Arabic characters |
926 |
1 |
| Characters of various other languages (Armenian, Bengali, Cyrillic, Devanagari, Georgian, Greek, Gujarati, Gurmukhi, Kannada, Lao, Malayalam, Oriya, Tamil, Telugu, Thai, Tibetan, etc.) |
1,907 |
1 |
| IPA phonetic alphabet and symbols |
219 |
2 |
| Symbols, marks, etc. |
2,556 |
2 |
| Other symbols and characters (ordinal number symbols; yin, yang and five elements characters; hotsuma characters; Abh [Banroh]) |
369 |
1 |
| Total: |
186,154 |
|
TRON Code's Language Specifier Codes
TRON Code language planes have been defined from plane 1 up to plane 31, and one can switch through the language planes using escape codes called "language-specifier codes." The number of characters that can be entered into one plane is 48,400 characters; this is a number that excludes such things as control codes from the information that can be expressed with two bytes. With character sets whose number of characters exceeds 48,400 (e.g., Dai Kan-Wa Jiten and the GT Typeface Font), we express them by using multiple language planes in parallel.
Approximately 1.5 million characters, which is the product of the number of language planes from plane 1 to plane 31 with these 48,400 characters, make up the character capacity of the TRON Code that has been implemented at present. Extension of the language-specifier codes is possible. By extending the number of character codes, in fact, it is possible to handle an unlimited number of characters.
 |
|
|
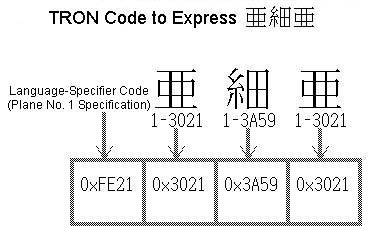
The concrete value of the language-specifier code for the number
N plane of the language planes (scripts) is 0xFEnn(nn=N+0x20)
(Fig. 2). For example, the language specifier code of the number
1 plane into which JIS X 0208 and the like have been entered becomes
0xFE21. On the other hand, the method
of specifying a particular character inside one of the language
planes is four-figure hexadecimal. Accordingly, in a case where
we express ![]() in
row 16 cell 1 of JIS X 0208 with TRON Code, because the hexadecimal
number corresponding to row 16 cell 1 is "0x3021,"
it becomes "0xFE21," "0x3021."
in
row 16 cell 1 of JIS X 0208 with TRON Code, because the hexadecimal
number corresponding to row 16 cell 1 is "0x3021,"
it becomes "0xFE21," "0x3021."
 |
|
In a case where the characters of the same language plane continue,
we can omit the language specifier code. For example, the TRON
Code in a case where we will express ![]() [ajia; 'Asia'] by inputting
[ajia; 'Asia'] by inputting ![]() on row 26 cell 57 (0x3A59) following
on row 26 cell 57 (0x3A59) following
![]() becomes "0xFE21," "0x3021,"
"0x3A59," "0x3021"
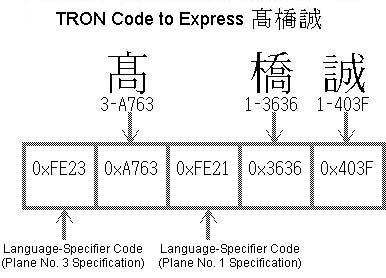
(Fig. 3). Moreover, in a case where we will express with TRON
Code a personal name such as
becomes "0xFE21," "0x3021,"
"0x3A59," "0x3021"
(Fig. 3). Moreover, in a case where we will express with TRON
Code a personal name such as ![]() [Takahashi
Makoto], because
[Takahashi
Makoto], because ![]() is assigned
to no. 60969 of the GT Typeface Font, in other words to 0xA763 of TRON Code plane no. 3 (0xFE23), the TRON Code becomes "0xFE23," "0xA763,"
"0xFE21," "0x3636,"
"0x403F" (Fig. 4).
is assigned
to no. 60969 of the GT Typeface Font, in other words to 0xA763 of TRON Code plane no. 3 (0xFE23), the TRON Code becomes "0xFE23," "0xA763,"
"0xFE21," "0x3636,"
"0x403F" (Fig. 4).
 |
|
Text Format TRON Code
Codes such as "0xFE21," "0x3021," etc, are things in which we express with a hexadecimal number the rows of binary format TRON Code stored in such things as files.
In a case where we indicate a particular character of TRON
Code inside text, there is also the method of expressing it as
X-YYYY. The X
is the specification of the language plane, and shows the decimal
number from 1 to 31; YYYY shows the
four-figure hexadecimal number. For example, ![]() becomes "1-3021." Instead
of this "1- " for expressing
the language plane, we can also use the hexadecimal number of
the language-specifier code and express it as
0xnnYYYY. In this case,
becomes "1-3021." Instead
of this "1- " for expressing
the language plane, we can also use the hexadecimal number of
the language-specifier code and express it as
0xnnYYYY. In this case, ![]() becomes "0x213021." Furthermore,
as a method for the purpose of making it clear that this is a
TRON Code character, there is also surrounding the hexadecimal
code value with "&T-;" and expressing it in the manner
of "&T213021;". This
method of expression is called "text format TRON Code"
(nicknamed &T format), and it
can be utilized as a technique for the purpose of expressing TRON
Code characters inside text data encoded with a character code
other than TRON Code.
becomes "0x213021." Furthermore,
as a method for the purpose of making it clear that this is a
TRON Code character, there is also surrounding the hexadecimal
code value with "&T-;" and expressing it in the manner
of "&T213021;". This
method of expression is called "text format TRON Code"
(nicknamed &T format), and it
can be utilized as a technique for the purpose of expressing TRON
Code characters inside text data encoded with a character code
other than TRON Code.
Text format TRON Code is supported by such things as the mail software and file conversion utility in the Cho Kanji series, and it is being practically used as an efficient means in cases where we handle character information expressed with TRON Code on a system other than Cho Kanji.
Compatibility Relationship with Existing Character Sets
In TRON Code, we have taken in as character sets without modification the source of several existing character codes. Table 9 is examples of the simple calculation formulas for the purpose of picking out correspondences between the code points on existing character sets (JIS full stop, etc.) and the character codes on TRON Code.
|
| The following are the TRON Code calculation formulas for a character in n row m cell in one of the respective character code standards. Furthermore, because every one of the following character sets have been placed on the first plane of TRON Code, the language-specifier code for all of them becomes 0xFE21. |
|
|
|
|
Even if, for the sake of argument, the respective values of the n row and m cell of JIS X 0208 and the n row and m cell of JIS X 0212 are the same, it is necessary to give them separate character codes on top of TRON Code. For that reason, on the JIS X 0212 side, we place bias on the character code values overall with a form in which add "0x80" to the higher level byte and make the MSB [most significant bit] 1, and thus we calculate in a manner in which there is no overlap with the assignment of JIS X 0208. It is the same also in regard to the code assignments of Chinese simplified characters (GB 2312 and Korean (KS X 1001).
In other words, TRON Code does not decide individual character code assignments on its own, rather it prepares a framework in a manner in which it can include as is existing character set standards, and thus it makes it its business to entrust to character code standards bodies that collect characters the definition of the individual characters [Note 4]. Accordingly, even newly decided character code standards and character sets can easily be included in TRON Code.
The concrete code assignments for all the characters of TRON Code are managed by the TRON Project, and they can be referenced from the "TRON Character Resource Center" Web page. Outside of the character codes of various nations, character sets such as the GT Typeface Font, the Dai Kan-Wa Jiten kanji collection, i-mode picture characters, Tompa characters, and hentaigana have been registered in TRON Code as independent character sets.
 |
|
|
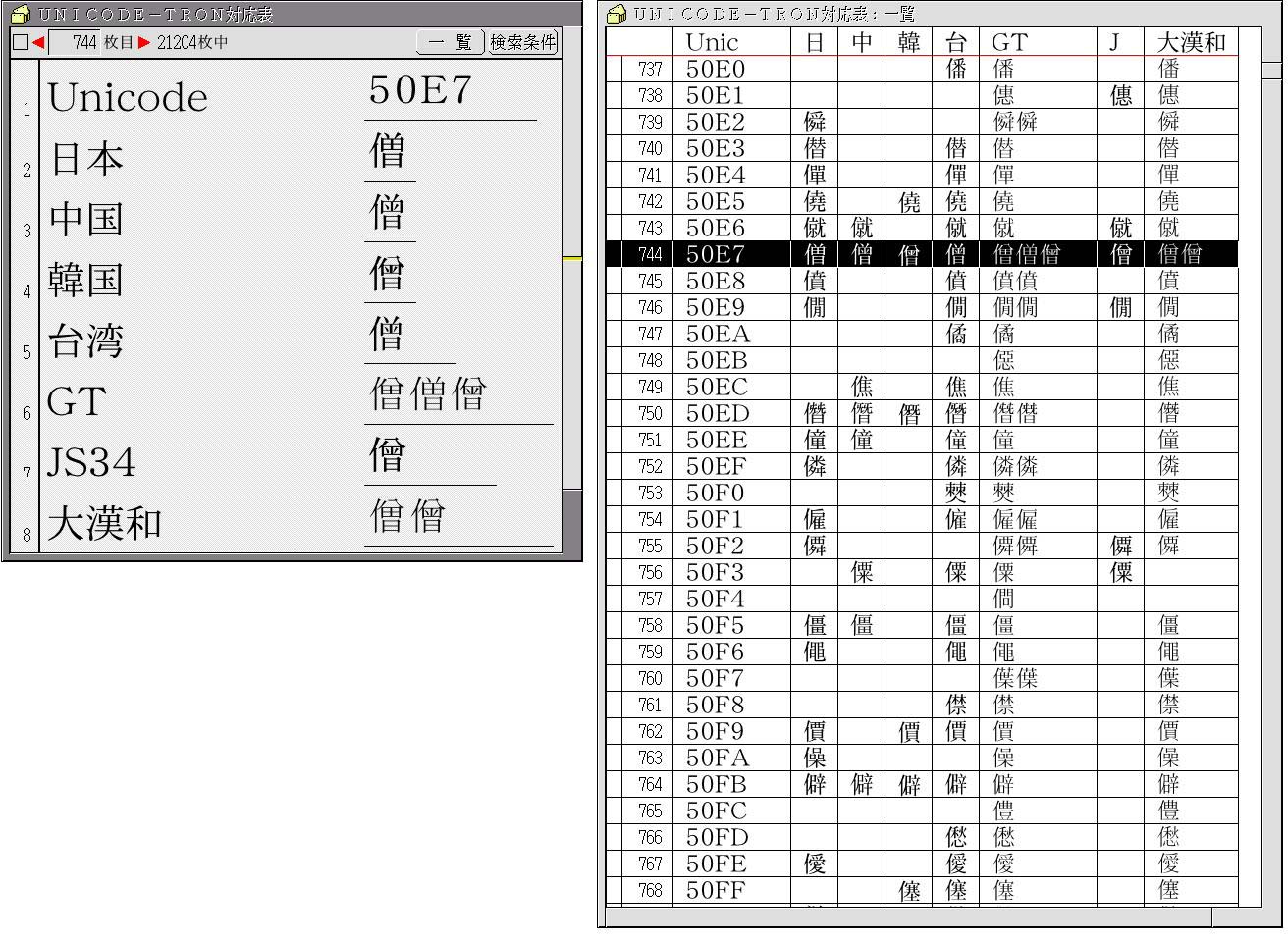
This policy is the exact opposite of Unicode, which ends up gathering characters that resemble each other from among the character code sources of various countries and then assigns one code to them. When we utilize this special feature, only with TRON Code can we even create a Chinese character correspondences table of Japanese, Chinese, Korean, etc., in the way that it is listed in the Unicode standard book, which is shown in Fig. 5.
"Cho Kanji V" is a desktop environment based on the BTRON-specification operating system that runs on top of the VMware Player virtualized environment. When we use Cho Kanji V, we can utilize various types of application software compatible with TRON Code on top of a Microsoft Windows personal computer. From here, we will introduce convenient features for the purpose of making practical use of TRON Code on Cho Kanji V.
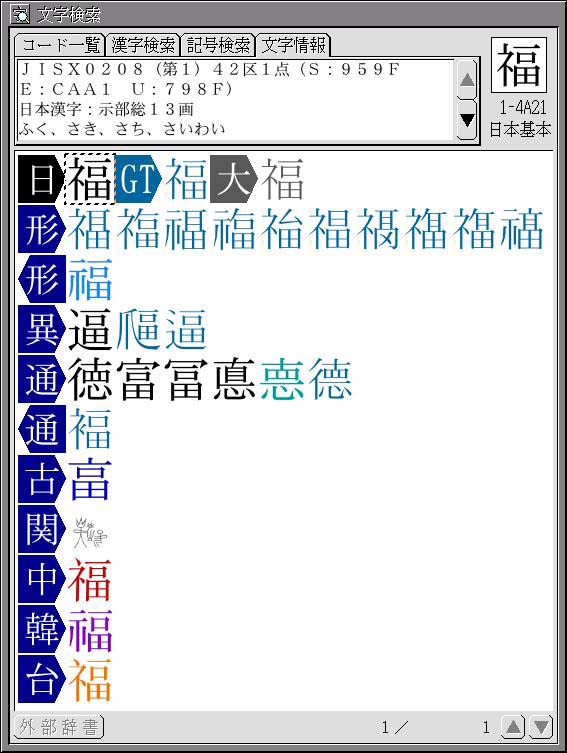
Character Search Utility
A total of more than 180,000 characters, such as alphabets, Chinese characters, and symbols, of various countries in the world are recorded in Cho Kanji V; what we have made so that users can easily search those characters from their readings and constituent parts is a utility software application called "Character Search."
Because we have registered as is multiple character sets in TRON Code, it is a fact that characters with the same character shape exist in duplicate among the different character sets. Also, whether it's the relationship of the upper and lower case letters of the alphabet or the relationship of the old character shapes and new character shapes of Chinese characters, a relatedness for each character exists. In the "Character Information" screen of Character Search, besides character attributes, such as the searched for character code number and readings, a list of related characters also is displayed.
The character that has been searched for can be pasted in text files or utilized as a file name with a copy and paste operation. Moreover, inputting it using kana-to-kanji conversion is also possible by registering it in a user dictionary for future use.
 |
|
In Fig. 6, we have just searched for ![]() with the Character Search utility and displayed its character
information. The
with the Character Search utility and displayed its character
information. The ![]() in
the GT Typeface Font and Dai Kan-Wa Jiten collected kanji
are written side by side as the same character shapes of
in
the GT Typeface Font and Dai Kan-Wa Jiten collected kanji
are written side by side as the same character shapes of ![]() in row 42 cell
1 of JIS X 0208. In addition, it is made up so that one will learn
the Chinese characters or characters with a strong relatedness,
such as lists of variants with old character shapes and those
used in personal names, plus the character shapes and character
codes of
in row 42 cell
1 of JIS X 0208. In addition, it is made up so that one will learn
the Chinese characters or characters with a strong relatedness,
such as lists of variants with old character shapes and those
used in personal names, plus the character shapes and character
codes of ![]() recorded
for the character sets of China, Korea, and Taiwan.
recorded
for the character sets of China, Korea, and Taiwan.
 |
|
|
Variant Character Swing Leveling
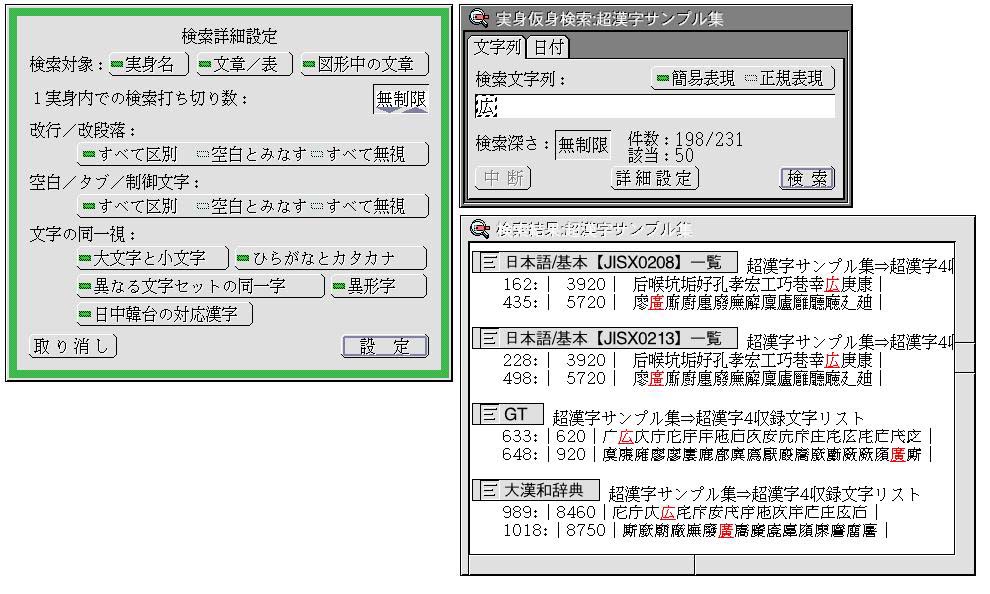
By using the Character Search utility, it has come about that we can easily find and freely handle the necessary characters. What's indispensable for the purpose of make practical use of created documents is a search function.
On top of TRON Code, because even characters with the same character shape are handled as different characters, we search by distinguishing all characters with the normal character string comparison routine. However, in a case where one intends to search for necessary information from among the large amount of contents that we have handled by mixing together multiple character sets, being unable to search outside of one or another character code is inconvenient.
Therefore, in Cho Kanji V, we support "variant character swing leveling," which can search for any character, without distinguishing among multiple character sets, if it is a character with the same character shape (Fig. 7).
For example, outside of row 16 cell 1 of JIS X 0208 (TRON Code:
1-3021), the Chinese character ![]() exists with the same character shape at no. 350 of the GT Typeface
Font (TRON Code: 2-2464) and main volume no. 272 of the Dai
Kan-Wa Jiten collected kanji (TRON Code: 8-2373). Also,
exists with the same character shape at no. 350 of the GT Typeface
Font (TRON Code: 2-2464) and main volume no. 272 of the Dai
Kan-Wa Jiten collected kanji (TRON Code: 8-2373). Also,
![]() of
of ![]() [Shenzhen],
which is a special economic zone in China, outside of locations
such as row 23 cell 23 of JIS X 0212 (TRON Code: 1-B737) and plane
1 row 15 cell 37 of JIS X 0213 (TRON Code: 1-2F45), also exists
at row 59 cell 58 of GB2312 (TRON Code: 1-4CDB), which is a Chinese
character set (Table 10). When we make "variant character
swing leveling" valid at search time, we can search without
distinguishing among these characters.
[Shenzhen],
which is a special economic zone in China, outside of locations
such as row 23 cell 23 of JIS X 0212 (TRON Code: 1-B737) and plane
1 row 15 cell 37 of JIS X 0213 (TRON Code: 1-2F45), also exists
at row 59 cell 58 of GB2312 (TRON Code: 1-4CDB), which is a Chinese
character set (Table 10). When we make "variant character
swing leveling" valid at search time, we can search without
distinguishing among these characters.
|
|
|||
|
|
|
|
 |
|
|
|
|
|
|
|
|
|
|
|
|
|
 |
|
|
|
|
|
|
|
|
|
|
|
|
|
Moreover, when we use the variant character swing leveling
function, not only can we search for characters with the same
shape among multiple character sets, but it is also possible to
simultaneously search for Chinese characters that are in a variant
character relationship, such as ![]() and
and ![]() .
.
Finally, as an actual example of programming in which we actually handle TRON Code, we will introduce a simple example program that runs on top of Cho Kanji.
In Cho Kanji V, we can utilize a character code conversion library called libtf. The libtf library, outside of being able to mutually convert among various types of character codes and TRON Code, possesses functions that search for and convert characters that correspond even among different character sets. The Cho Kanji development environment and its documentation, which includes documentation on libtf, is distributed via Personal Media Corporation's Cho Kanji developer's Web site.
Table 11 is a list of the functions provided in libtf. List 1 is an example in which we have created a program (libtftest) in which we use libtf to convert TRON Code into EUC and then display it in dump format.
|
|
||
|
tf_open_ctx | Acquire processing environment |
| tf_close_ctx | Release processing environment | |
|
tf_to_id | Search for ID from ID class and keyword |
| tf_id_to_idtype | Search for ID class from ID | |
| tf_id_to_str | Search for keyword character string from ID | |
| tf_id_property | Acquire properties from ID | |
| Character code setting | tf_set_profile |
|
|
tf_tcstostr | Convert TC[] to external character code |
| tf_wtcstostr | Convert WTC[] to external character code | |
| tf_convtostr |
|
|
| tf_strtotcs | Convert external character code to TC[] | |
| tf_strtowtcs | Convert external character code to WTC[] | |
| tf_convfromstr |
|
|
| Conversion option | tf_set_options | Set conversion time options |
|
tf_init_charset | Initialize character set set information |
| tf_query_charset_tcs | Look for character set that can express TC[] | |
| tf_aggregate_charset_tcs |
|
|
| tf_aggregate_charset_wtcs |
|
|
| tf_query_charset |
|
|
In Cho Kanji, there are applications that start up from virtual objects (icons) and accessory (utility) menus, and there are cli applications that use the command line of the console for development use; the sample program on this occasion corresponds to the latter. In a case where we start up from a virtual object or the accessory menu, the MAIN() function becomes the entry, and information concerning startup also is handed over in a structure. In the case of a cli application, the general main() function in UNIX, etc., becomes the entry, but the character string is handed over not with char, but rather with TRON Code.
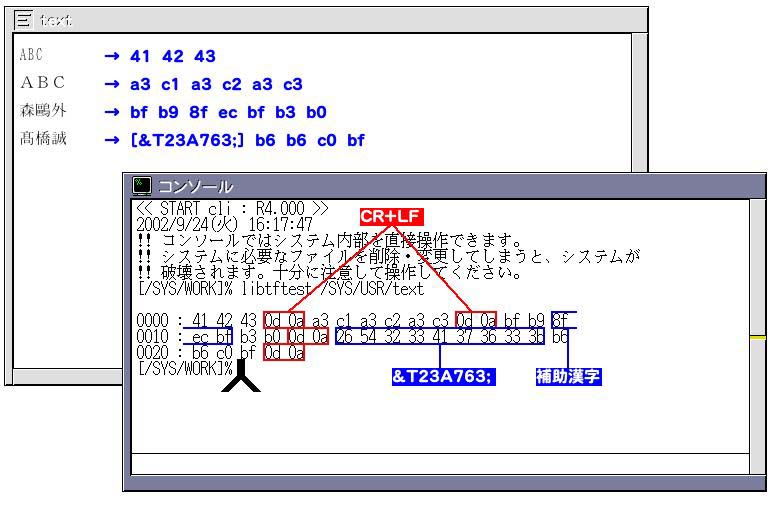
So that a slash and so on can be used in the file name, we indicate path breaks with special characters in the APIs. Accordingly, we convert the path name specified in the argument with cnvpath().
We open the file with readfile(), and then we read into the memory the TAD main record. Incidentally, TAD is an abbreviation of TRON Application Databus, and it refers to standard data formats on top of BTRON, including Cho Kanji. Also, a BTRON file is organized from multiple records, and, as for data such as text, figures, and images, the record types among those are stored in one TAD main record.
 |
|
|
In the part where we call up libtf, we first open a processing environment in setup_tc(), an then we set up "Convert to EUC-JP." By means of this, we convert into EUC code data described with TRON Code on top of Cho Kanji. At this time, in a case where characters have appeared that cannot be expressed with EUC-JP, such as the GT Typeface Font, we have made the setting to convert to text format TRON Code (&T format). With libtf, in order to process only the character strings included in TAD, we pass the main TAD record that has been read in as is to the libtf function called tf_tcstostr(), and then we dump the conversion results obtained by means of that. We show in Fig. 8 the results of having input into this sample program a text in which characters of JIS Level 1 and JIS Level 2, JIS Auxiliary Kanji, and the GT Typeface Font are mixed together.
Inside the source program, if we change the parameter tf_to_id() that indicates "EUC-JP" to another character set name, we can also convert to various character codes outside of EUC-JP.
As for settings related to the character set, we can flexibly carry this out by means of an ID class and character string combination. For example, we can carry out conversion by specifying in tf_set_profile() the ID searched for as tf_to_id(TF_ID_PROFSET_CONVERTFORM, "EUC=JP"), and then calling tf_strtotcs().
Moreover, we can also set whether to convert ASCII 0x5c to, either "\" or "yen sign," by specifying in tf_set_option() the ID searched for as tf_to_id(TF_ID_OPT_CONVERT, "SBCHAR_5C"). We can also set methods of processing for such things as half-width kana, "grave accent mark" and "equivalency sign - tilde," undefined characters and characters that cannot be converted, broken data, and line change codes. It is also possible to specify the buffer size with an option.
We can utilize the character set detection function in selecting an appropriate character code in something such as mail encoding, for example. When we input the target character string in tf_aggregate_charset_tcs() after calling tf_init_charset(), the character set's set information gets narrowed down. And then, for example, by handing over to tf_query_charset() the ID searched for with tf_to_id(TF_ID_SETOFCHARSET, "MESSAGE_JP"), information is obtained as to whichever--"US-ASCII," "ISO8859-1," "ISO2022-JP," ISO2022-JP2," "ISO2022-JP3," "UTF-8"-- the character strings input up to now can be converted.
In this article, we have provided not just a technical explanation of TRON Code, but rather a variety of issues concerning enormous dataware, including Chinese characters and the complexities of handling Chinese characters.
The code system itself called TRON Code is something independent of an operating system. It is possible to create applications that handle TRON Code even on operating systems with a Windows and UNIX lineage, and not just Cho Kanji. In particular, if one utilizes text format TRON Code, then while mixing character codes one has used heretofore, one can utilize, in a form that expands that, Chinese characters and other characters that have been adopted in TRON Code. Moreover, we have also prepared various types of applications for converting text so that one can view even on top of an operating system's word processors and browsers contents created on Cho Kanji V.
The development of practical systems that go beyond the character code and operating system framework and make use of TRON Code is to be looked forward to in the future.
____________________
| libtftest.c |
/* This source is for explaining libtf operations; there are the following limits. */
/* - It is premised on the beginning starting script 0x21. */
/* - TAD main record is made up so that only text can be loaded. */
/* - There will be no text nesting. */
#include <basic.h>
#include <tcode.h>
#include <bstdio.h>
#include <bstdlib.h>
#include <bstring.h>
#include <tstring.h>
#include <errcode.h>
#include <btron/btron.h>
#include <btron/libapp.h>
#include <btron/tf.h>
#define DEBUGPRINT 2
#define TARGET "libtftest"
#if DEBUGPRINT
#define DERROR(y, z) printf("%s[%d]>%s(%d/%x)\n", TARGET, prc_sts(0, NULL, NULL), y, z>>16, z)
#define DPATH1(x) printf("%s[%d]>%s\n", TARGET, prc_sts(0, NULL, NULL), x)
#define DPATH1F(x) (printf("%s[%d]>", TARGET, prc_sts(0, NULL, NULL)), x)
#else
#define DERROR(y, z) /**/
#define DPATH1(x) /**/
#define DPATH1F(x) /**/
#endif
#if DEBUGPRINT > 1
#define DPATH2(x) printf("%s[%d]>%s\n", TARGET, prc_sts(0, NULL, NULL), x)
#define DPATH2F(x) (printf("%s[%d]>", TARGET, prc_sts(0, NULL, NULL)), x)
#else
#define DPATH2(x) /**/
#define DPATH2F(x) /**/
#endif
#if DEBUGPRINT > 2
#define DPATH3(x) printf("%s[%d]>%s\n", TARGET, prc_sts(0, NULL, NULL), x)
#define DPATH3F(x) (printf("%s[%d]>", TARGET, prc_sts(0, NULL, NULL)), x)
#else
#define DPATH3(x) /**/
#define DPATH3F(x) /**/
#endif
#if DEBUGPRINT > 3
#define DPATH4(x) printf("%s[%d]>%s\n", TARGET, prc_sts(0, NULL, NULL), x)
#define DPATH4F(x) (printf("%s[%d]>", TARGET, prc_sts(0, NULL, NULL)), x)
#else
#define DPATH4(x) /**/
#define DPATH4F(x) /**/
#endif
LOCAL W size = 0;
LOCAL VOID *buffer_src = NULL;
LOCAL TF_CTX tc0;
EXPORT VOID killme()
{
ext_prc(0);
}
LOCAL readfile(TC *path)
{
W err;
LINK lnk0;
W fd0;
/* Convert path into link structure */
if ((err = get_lnk(path, &lnk0, F_NORM)) < 0) {
DERROR("get_lnk", err);
return err;
}
/* Open the file */
if ((fd0 = opn_fil(&lnk0, F_READ, NULL)) < 0) {
DERROR("opn_fil", fd0);
return fd0;
}
/* Search TAD main record */
if ((err = fnd_rec(fd0, F_TOPEND, 2, 0, NULL)) < 0) {
DERROR("fnd_rec", err);
cls_fil(fd0);
return err;
}
/* Acquire record size */
if ((err = rea_rec(fd0, 0, NULL, 0, &size, NULL)) < 0) {
DERROR("1st.rea_rec", err);
cls_fil(fd0);
return err;
}
if (size <= 0) {
DERROR("size", size);
cls_fil(fd0);
return ER_NOEXS;
}
/* Confirm read-in buffer */
if ((buffer_src)) {
free(buffer_src);
buffer_src = NULL;
}
if ((buffer_src = malloc(size)) == NULL) {
DPATH1("no memory.");
cls_fil(fd0);
return ER_NOMEM;
}
/* Read in record */
if ((err = rea_rec(fd0, 0, buffer_src, size, NULL, NULL)) < 0) {
DERROR("2nd.rea_rec", err);
cls_fil(fd0);
return err;
}
/* Close file */
cls_fil(fd0);
return 0;
}
LOCAL W setup_tc()
{
static W first = 1;
W err;
W id0;
/* Acquire processing environment */
if (first == 0)
;
else if ((err = tf_open_ctx(&tc0)) < 0) {
DERROR("tf_open_ctx", err);
return err;
} else
first = 0;
/* Acquire ID corresponding to "conversion destination EUC-JP" */
if ((id0 = tf_to_id(TF_ID_PROFSET_CONVERTTO, "EUC-JP")) < 0) {
DERROR("1st.tf_to_id", id0);
return id0;
}
/* Set the processing environment */
if ((err = tf_set_profile(tc0, id0)) < 0) {
DERROR("tf_set_profile", err);
return err;
}
/* Acquire ID corresponding to "non-convertible character processing option" */
if ((id0 = tf_to_id(TF_ID_OPT_CONVERT, "UNSUPPORTED_CHAR")) < 0) {
DERROR("2nd.tf_to_id", id0);
return id0;
}
/* Set options (non-convertible characters &T format" */
if ((err = tf_set_options(tc0, id0, 2)) < 0) {
DERROR("tf_set_options", err);
return err;
}
return 0;
}
EXPORT W main(W ac, TC **av)
{
W err;
TC *path;
/* Read in file */
switch (ac) {
case 2:
break;
default:
printf("usage : libtftest <filename>\n");
killme();
}
/* Convert path punctuation into special characters */
if ((path = cnvpath(av[1])) == NULL) {
DPATH1("cnvpath");
killme();
}
if (readfile(path) < 0)
killme();
/* Set up the processing environment */
if (setup_tc() < 0)
killme();
{
#define BUFFERSIZE 256
W first, cont;
W offset, len;
UB buffer_dst[BUFFERSIZE];
first = 1;
offset = 0;
cont = 0;
do {
W pos;
/* Conversion processing */
len = sizeof(buffer_dst);
if ((first)) { /* 1st time */
if ((cont = tf_tcstostr(tc0, buffer_src, size / sizeof(TC), TSC_SYS, TF_ATTR_START, buffer_dst, &len)) < 0) {
DERROR("1st.tf_tcstostr", cont);
killme();
}
first = 0;
} else if ((cont = tf_tcstostr(tc0, NULL, 0, 0, 0, buffer_dst, &len)) < 0) { /* From 2nd time on (in a case where
having been processed a 1st time) */
DERROR("2nd.tf_tcstostr", cont);
killme();
}
/* Dump processing */
for (pos=0; pos<len; pos++) {
if ((offset & 0xf) == 0)
printf("\n%04x :", offset);
printf(" %02x", buffer_dst[pos]);
offset++;
}
} while (cont > 0); /* In a case where output didn't finish on 1st time, repeat */
printf("\n");
}
killme();
}
/* End of file */
|
____________________
[Note 1] Chinese characters created in Japan are called kokuji [national characters].
[Note 2] Generally, in order to distinguish upper case and lower case letters, the actual alphabet types come to double this, or 52 types.
[Note 3] JIS X 0212 is utilized together with JIS X 0208.
[Note 4] As for a macro explanation of TRON Code, as mentioned in this article, the TRON Project itself does not carry out the assigning of individual character codes. However, on two points, there are exceptions. First, the "GT Typeface Font" that is recorded in TRON Code is not the result of the activities of the TRON Project itself, but because the TRON Project is cooperating in the activities of the GT project, it comes down to the fact that the TRON Project also participates in the individual character code assignment work of the GT project. Also, although they are comparatively small scale, there exist several character sets, such as Braille and ordinal number symbols, for which the TRON Project itself has carried out the assigning of individual character codes, and there is the possibility that these cases could increase also in the future.
____________________
[Translator's Note 1] Chinese characters are mainly used in China, Japan, and Korea (CJK), where they are respectively called hanzi, kanji, and hanja. They were also used at one time in Vietnam, which is why the processing of Chinese characters is sometimes referred to as CJKV.
[Translator's Note 2] The wards of Tokyo now use the term "city" in their official English titles, although they still use the kanji character for ward, ku, in their official Japanese titles. In this translation, in order to avoid confusion on the part of readers living overseas, the translator has decided to use the conventional term ward, since this is an article about the processing of Chinese characters, not the special administrative powers of Tokyo's wards in comparison to the wards of other Japanese cities.
[Translator's Note 3] Gaiji literally means 'outside character(s)', which is to say characters that do not have fixed character codes and thus are external to the computer system or computer architecture on which the computer system is based. TRON Code, as stated in many sources heretofore, rejects the concept of gaiji, which are also referred to as "user defined characters," at the operating system level. Accordingly, there is no "user defined region" within TRON Code.
[Translator's Note 4] The translation of the active window, which is titled "Console," is as follows:
The white kanji on a blue background translate as: "Auxiliary Kanji."
Copyright © 2009 Personal Media Corporation
Copyright © 2009 Sakamura Laboratory, University Museum, University of Tokyo