
In T-Kernel/Standard Extension (hereafter T-Kernel/SE), we provide memory process management that utilizes an MMU [1] and a file system function for T-Kernel. Also, including these representative functions, the following functions have been added and/or extended.
|
I will now go on to explain in this article the individual functions that T-Kernel/SE possesses and their concepts.
The memory management function is one of the most important functions among those in T-Kernel/SE. Function extensions in which an MMU is utilized have been carried out in order to realize process functions and virtual memory [2], in particular.
Logical Address Space and Memory Protection
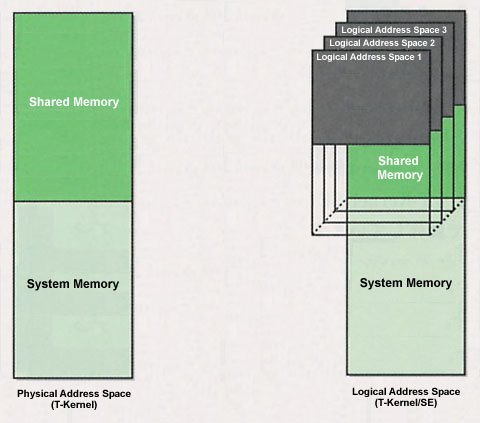
In T-Kernel/SE, we support logical address space (task space) by utilizing an MMU. For example, in the case of T-Kernel, all programs are operating in a single physical address space. In contrast to this, in T-Kernel/SE, we have multiple logical address spaces, and application programs [3] operate in individual logical address space (Fig. 1).
 |
|
|
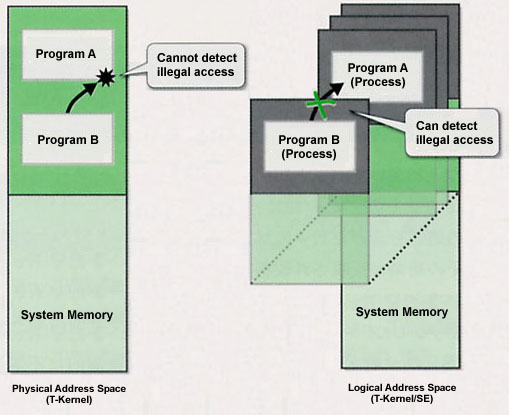
At this time, in a T-Kernel that does not utilize an MMU, we cannot detect illegal access to memory (Fig. 2). On the other hand, in T-Kernel/SE, we can limit access to different logical address spaces and access to the system region. For that reason, even if some programs try to illegally access memory, we can detect this and keep that damage to a minimum.
 |
|
|
 |
|
|
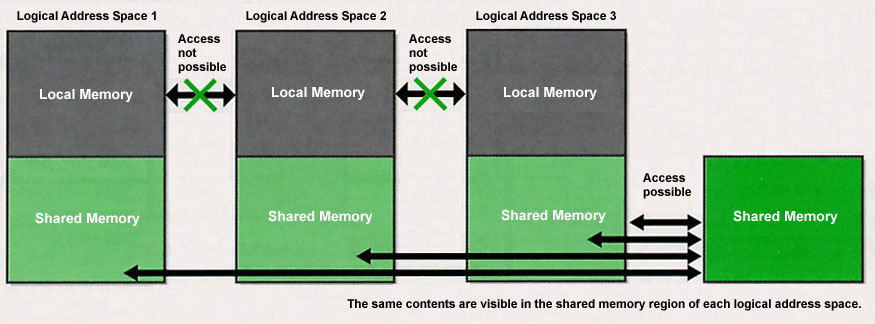
Local Memory and Shared Memory
In logical address space, memory regions with different attributes, called local memory and shared memory, exist (Figs. 1, 3). Also, separate from these, a system memory region exists as a region that cannot be accessed except from a system level program (Fig. 1). The differences in these memory regions are as follows:
|
|
|
Inside each memory region, applications dynamically acquire memory in regard to local memory regions and shared memory regions, and using these as work memory is possible. Furthermore, in a case where applications use these regions as work memory, we basically make it so that they use the local memory regions. No matter what, we make it so that applications use shared memory regions only in cases where we would like to carry out exchange of data among different processes (logical address spaces).
Process/task management is a management function that carries out management of processes, task scheduling, and the like.
What's a process?
In regard to a process, it has already been mentioned in the previous section, but when looked at on the T-Kernel level, its substance comes down to "multiple tasks + logical address space + a resource group." And then, as for tasks that belong to the same process, they operate in the same logical address space (task space), and they share the same resources. Also, each process' unique management data are retained in the resource group of the process. Among these are also included such things as what tasks are included in the process, and how the parent child relationships are made up among the processes.
Parent Process and Child Process
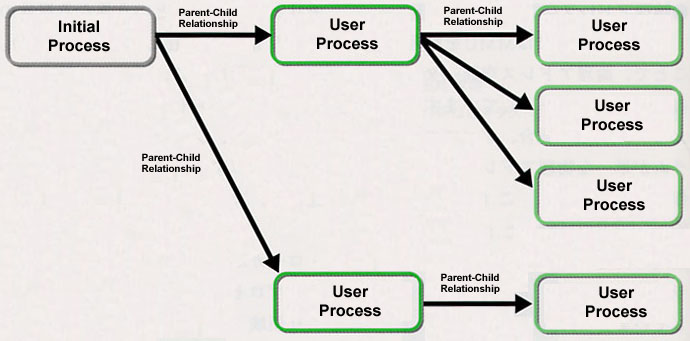
Each process comes to create new processes as the need arises. At this time, a process that a process itself has created is a child process, and that process itself becomes the parent process of that child process. Also, in a case where a process has created a child process, a portion of the data that the parent process holds is inherited by the child process. When we make as an example the entire T-Kernel/SE system, we first create a special process called the initial process at the time of startup. Normally, we make it so that we go on to generate from this initial process the processes that will become the user processes. Also, in accordance with need, it will come about that we will go on to create new processes. At this time, the system overall process configuration becomes a tree structure in which we make the initial process the root (Fig. 4) [4].
 |
|
|
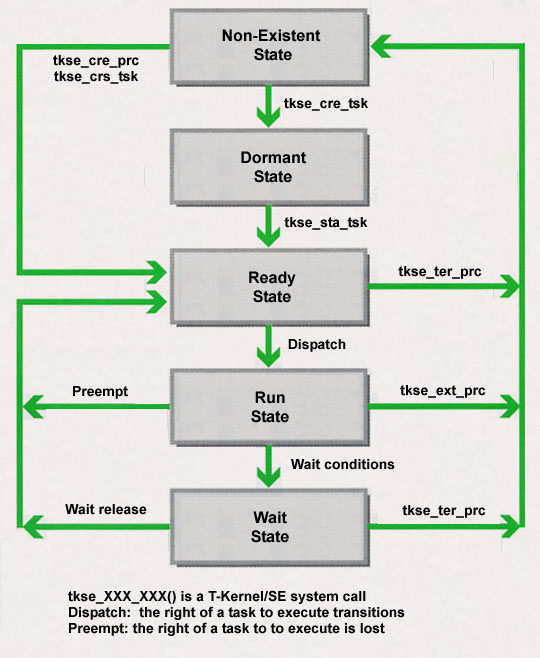
Process/Task State
Even in a process, state exists in the same manner as a T-Kernel task. The process state shows the main task state, and it possesses one of the following states (Fig. 5).
|
In addition, subtasks also possesses the same states as processes, but depending on the call-up of a system call [5], there is also one in which the subtask becomes:
|
 |
|
|
Process/Task Priority Level and Scheduling
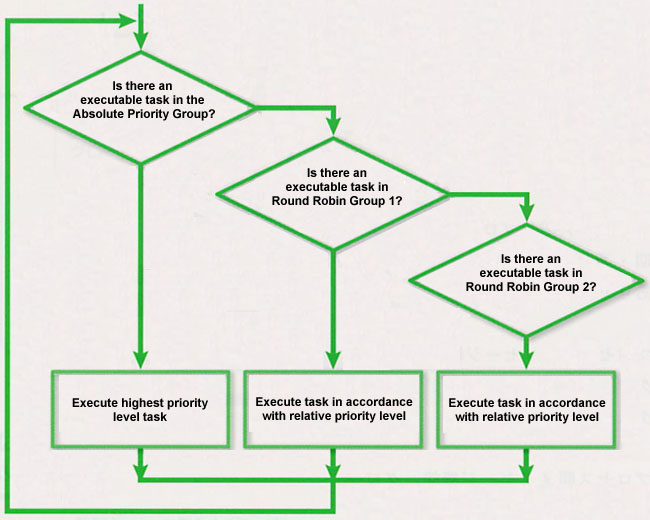
In regard to the priority level of a process (main task) or a subtask, it is classified into one of the following three groups, depending on its value.
|
 |
|
|
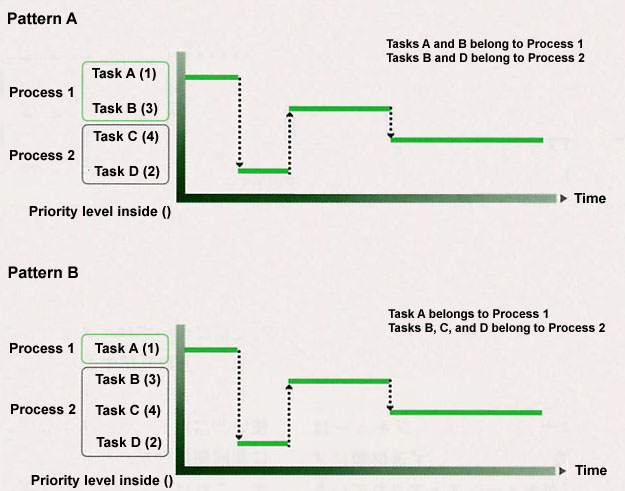
And then, following the flow in Fig. 6, processing in the executable tasks comes to switch in the order of Absolute Priority Group → Round Robin Group 1 → Round Robin Group 2. Furthermore, at this time, the scheduling of each task is not dependent upon the process it belongs to. For example, as in Fig. 7, task switching occurs in accordance with the task priority level, without regard to the process to which it belongs.
 |
|
|
As for functions for synchronization/communication among processes/tasks in T-Kernel/SE, there are the following three types.
|
As for the message function among processes and the global name function, they are functions that are newly added in T-Kernel/SE; and, as for the synchronization/communication function, functions that are almost the same as T-Kernel can be used.
 |
|
|
Message Function among Processes
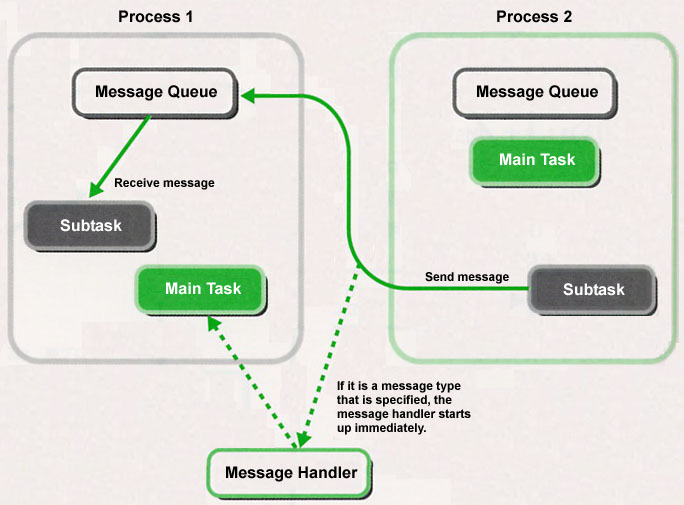
This function is a function for sending and receiving messages among processes. In each process, there is a unique message queue, and we carry out message communication through this message queue (Fig. 8). Also, this isn't just communication among application processes, rather we use it also in system-related communication, such as the termination of a child process. In addition, in regard to timeout messages and the like, we can send them to and receive them from not just other processes, but also to/from the self process.
The message queue of each process is made up as FIFO, and the messages are always stored in the queue in the order sent. At this time, in a case where the message queue of the address to where the message will be sent is full, it is possible to specify such things as whether to wait until a space is readied in the queue or whether to return an error. Also, in regard to receiving, fetching based on a message's receive request is possible.
As for other things, it is also possible to carry out asynchronous processing at the time of receiving a specified type message using a message handler. This can be used as a type of interrupt processing (Fig. 8).
The message handler itself is a function for the purpose of asynchronously processing a receive message with the processes currently being executed, and we define it as a function compatible with a message type. And then, in a case where the corresponding message type has been received, the message handler is executed in a form in which it interrupts the current process of the main task (it is possible to simultaneously define a maximum of 31 types of message handlers compatible with various message types).
|
|
|
| Message Type | Definition Name |
| Process abnormality termination message | MS_ABORT |
| Process normal termination message | MS_EXIT |
| Process forced termination message | MS_TERM |
| Timeout message | MS_TMOUT |
| System event (forced termination) | MS_SYSEVT |
| System message | MS_SYS1~MS_SYS5 |
| Application definition message | MS_TYPE0~MS_TYPE7 |
| Reservation message | MS_MNG0~MS_MNG12 |
Global Name Manager
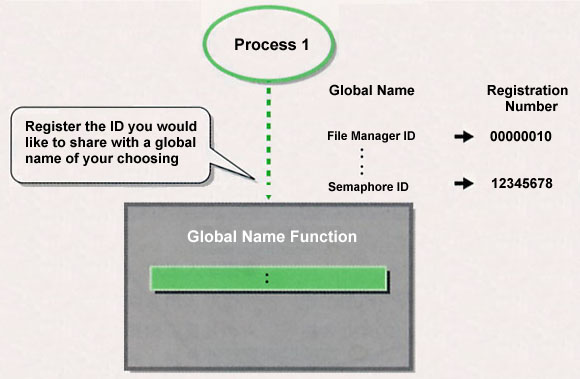
The global name manager is a function that attaches and manages arbitrary names to data values you want to share among processes. It is convenient if we mange with this function environment parameters that we use system wide, and object IDs that we share among processes [6].
For example, with dynamically assigned object IDs, such as semaphores and message buffers, the specific ID is not known until that object is actually created. For that reason, outside of the process that created the object, it is necessary to confirm that object ID after process startup. In this type of case, we use the global name management function doing as follows:
|
|
We decide and lay down beforehand a "global name" corresponding to each object as the deciding factor of an application |
|
|
Initially, a process (or task) that has created an object registers that object ID and its global name using the global name function (Fig. 9 [a]) |
|
|
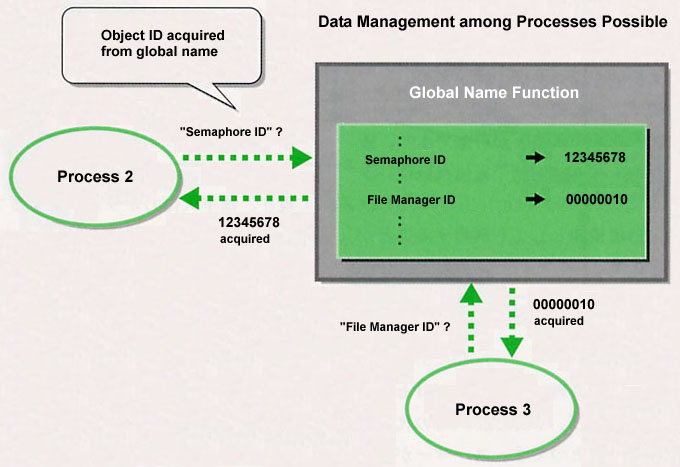
Other processes that want to share objects acquire registered object IDs by means of the global names of those objects (Fig. 9 [b]) |
 |
|
|
 |
|
|
By doing things in this manner, we can easily manage object IDs that we would like to share among processes.
 |
|
|
Synchronization/Communication Function among Tasks
In the synchronization/communication function among tasks, we have prepared the same objects as the synchronization and communication objects that exist in T-Kernel. As for the specific synchronization/communication objects, they are in accordance with Table 2.
|
|
|
| Object |
|
| Semaphore | By numerically expressing the presence or absence of resources and their numerical amount, an object that carries out exclusion control and synchronization of those resources |
| Mutex | An object for carrying out exclusion control among tasks when using resources; possesses a function for preventing the reversal of priority levels |
| Event flag | An object that carries out synchronization by expressing the presence or absence of an event with a flag on each bit |
| Message buffer | An object that carries out synchronization and communication through the receiving and passing on of variable length messages |
| Rendezvous | An object that carries out synchronization and communication by supporting processing requests to other tasks and the processing of the chain in which those processing results are received |
| Mailbox | An object that carries out synchronization and communication by receiving and passing on messages that have been placed in memory |
Functionally, this is almost the equivalent to the synchronization/communication function that T-Kernel possesses, but at the time of process termination, it is possible to specify such things as whether or not to delete the synchronization/communication object among tasks that that process created.
Furthermore, when we say a synchronization/communication function among tasks, you might be led to think that it is an object that can only be used among tasks inside the same process. However, leaving aside the mailbox function, accessing the same synchronization/communication object among all processes is possible [7]. For that reason, the synchronization/communication function among tasks is not just among tasks, rather it can also be utilized as a synchronization/communication function among processes.
File management, as well as the memory/process management functions, is one of the representative functions of T-Kernel/SE. This is a necessary function when using virtual memory, both at the time user carries out a file operation, and when we load a program from the file system. Furthermore, as interfaces for the user to carry out file operations, "standard input/output" and "standard file system management" have been prepared.
 |
|
|
Standard Input/Output
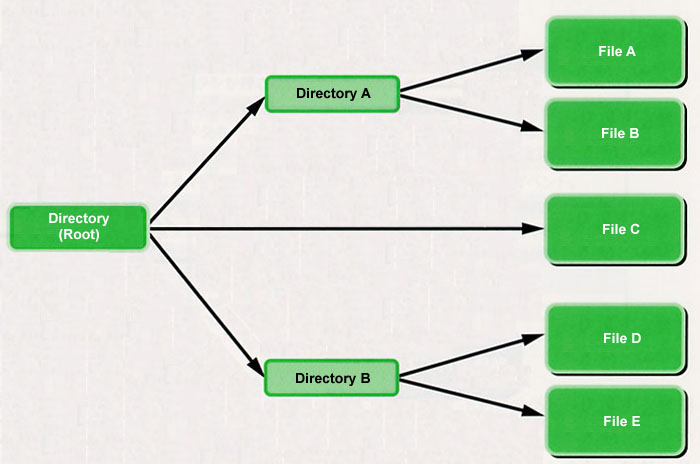
Standard input/output is an interface for handling file operations in a unified manner without relation to the differences in the various types of file systems. The interface follows the file system of a hierarchical directory structure (Fig. 11), and handling is the same as a general file system, such as FAT. In addition, a library (corresponding to a standard C library) utilizing standard input/output has also been prepared, and it even provides numerous functions implemented at the library level.
File Systems Standard Input/Output Supports
At present, the file systems that standard input/output supports are the following three types. Furthermore, adding on new file system is also possible.
- T-Kernel (TRON) standard file system: a file system that possesses a network structure [8].
- FAT file system: compatible with FAT12, FAT16, FAT32 (compatible with long names)
- CD-ROM file system: compatible with the file system of ISO9660 Level1; supports readout only
Method of Specifying the File System
The file path specification is in the following format.
/connect name/directory name/file name
(e.g.) /SYS/lib/libsample.so
In this case, the " / " at the beginning is the root directory, which is a virtual directory exclusively used in read in. And then, the directory immediate below the root directory shows the file system that is connected. In the example, the attached file system is made up with the connection name "SYS."
Also, such specifications as current directory, self directory, and parent directory are also possible. This is the same as a general file system with a hierarchical directory structure.
- Current directory: each process retains its respective current directory, and using a relative path is possible; also, directory information is handed over from the parent process to the child process at the time of process creation
- Self directory and parent directory: in all directories, using " . " in the path name of the self directory, and " .. " in that of the parent directory is possible
 |
|
|
Standard File System Management
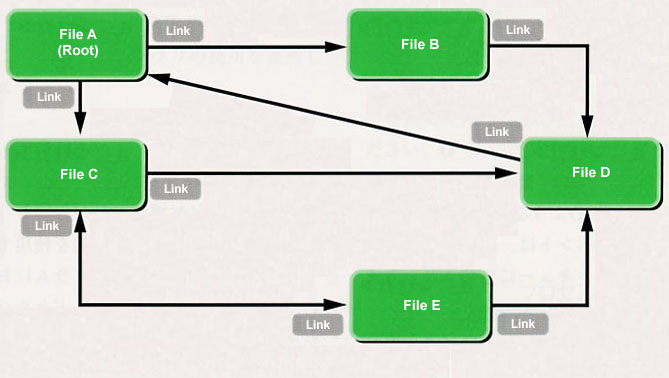
Standard file system management is the interface for exclusive use of the T-Kernel standard file system. I recommend the use of standard input/output for normal file operations, but it is necessary to use this interface in a case where you will use the original functions of T-Kernel standard file system. Furthermore, the T-Kernel (TRON) standard file system is a file system with a network structure in which files are connected together with links (Fig. 12). I will leave out the details, but there is no concept of a directory in the manner of the FAT file system.
 |
|
|
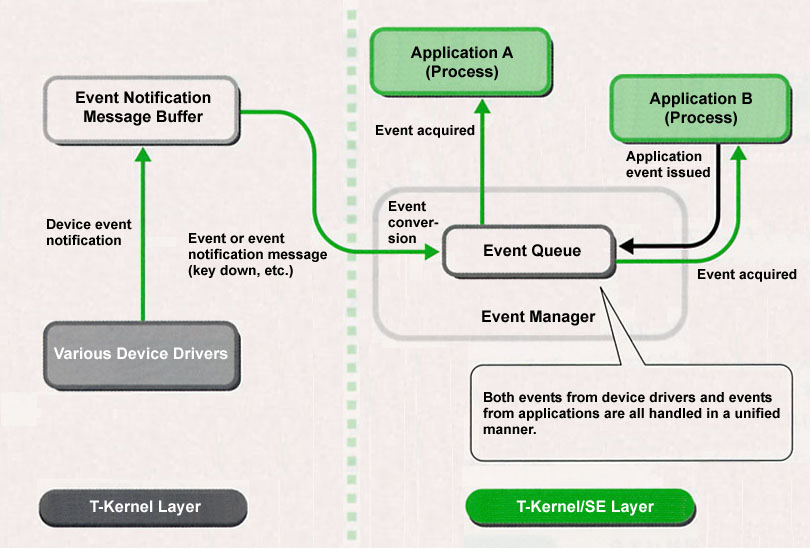
Event Manager
The event management function is a function for handling in a unified manner control events, such as those of the keyboard and pointing device, and events reported by various device drivers. Moreover, it is possible to issue direct application events also from user programs (processes), and events including these can be handled in a unified manner (Fig. 13).
As for the types of events that the event manager handles, there are the ones as in Table 3.
|
|
||
| Event | Definition Name |
|
| Button down event | EV_BUTDWN | An event generated when the pointing device button is pressed |
| Button up event | EV_BUTUP | An event generated when the pointing device button has been released |
| Key down event | EV_KEYDWN | An event generated when an ordinary key outside of a special key (meta key), such as a shift key, is pressed |
| Key up event | EV_KEYUP | An event generated when an ordinary key outside of a special key (meta key), such as a shift key, is released |
|
EV_AUTKEY | An event generated cyclically when a key that is subject to auto-repeat is pressed and held down |
| Device event | EV_DEVICE | A general event that occurs following a change in a device other than the keyboard and pointing device |
| Null event | EV_NULL | A pseudo event that shows that the event that is the object has not been generated |
| Application event |
|
An event that an application arbitrarily defines and uses; can be used as a communication function among applications |
|
EV_EXDEV | An event in which we append extended information (16 bytes in length) to a device event (EV_DEVICE) |
These events go on to be stored in a common event queue that the system possesses. And then, it comes about that applications take out these sequential events from this event queue and go on to execute processes compatible with these.
 |
|
|
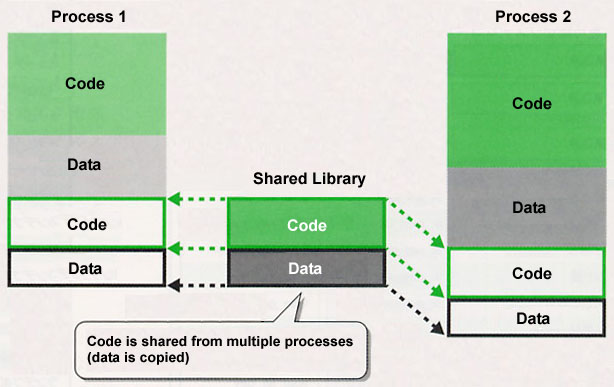
In T-Kernel/SE, it is possible to dynamically share one library code among multiple processes. The merit of this function lies in the point that we can make the code size of each process program smaller by dynamically linking shared code (Fig. 14). Also, as the name implies, we can collect the shared code together in one module.
In a case where we will actually use the shared library function, it is necessary to carry out the loading of the shared library and symbol resolution in each process program. As to the loading of this shared library and symbol resolution, there are the following two patterns.
|
|
In a case where you'll explicitly utilize it by employing library functions
|
|
|
In a case where you'll automatically utilize it at the time of process creation
|
Furthermore, the shared library function is dependent on language-type processing functions, such as compilers and linkers. For that reason, in creating a shared library, there is a need for language processing type functions to possess a function that creates Position Independent Code.
As there are functions that it is possible to utilize from applications even outside of the functions explained up to here, I would like to introduce them for future reference.
Device Manager
This is a function for utilizing device drivers. In T-Kernel/SE we have removed the device registration function, and we have provided a function equivalent to the T-Kernel device management function.
Time Manager
This is a function for carrying out time management, such as the system time. In T-Kernel/SE, we provide a function equivalent to the time management function of T-Kernel.
System Management
As functions for system management, we provide:
This is not something that is part of the OS functions, but functions corresponding to a standard C library are provided. When creating a user application, from the point of view of portability and so on, we recommend using this library.
I have given an introduction that skims over the various functions; did you grasp a general image of the functions that T-Kernel/SE provides? Furthermore, as to the detailed specification of the system calls, it is planned to make it public along with the source code. Also, if you are a T-Engine Forum [9] A or B member, you can obtain the documentation of the latest specification from the member page, so, by all means, please try to make use of it.
____________________
[1] MMU: Memory Management Unit; this is hardware for the purpose of carrying out such things as the mapping and protection of memory.
[2] Virtual memory: a virtual memory region that exceeds the actual memory size.
[3] Generally, what we call a T-Kernel/SE application refers to a process base program.
[4] A parent process does not exist in the initial process. Also, in a case where the initial process has terminated, the system exceptionally changes into a state in which the parent process of that child process does not exist.
[5] System call: an application program interface (API) that directly calls up an OS function. In the case of T-Kernel/SE, "tkse_xxx_xxx()" corresponds to this.
[6] One global name can be registered with a maximum 512 bytes in length (256 characters in TC = TRON Code form).
[7] It is possible to use a mailbox function only inside the same process for the purpose of address passing messages.
[8] In standard input/output, things are arranged so that we can falsely handle it as the file system of a hierarchical directory structure.
The above article on T-Kernel appeared on pages 24-33 in Vol. 99 of TRONWARE . It was translated and loaded onto this Web page with the permission of Personal Media Corporation.
Copyright © 2006 Personal Media Corporation
Copyright © 2006 Sakamura Laboratory, University Museum, University of Tokyo