
VACS Corporation's Japanese input system VJE-Delta Ver. 2.5 has been loaded onto the newly marketed B-right/V [operating system]. For that reason, we had a person at VACS contribute a general outline of Japanese input systems.
There are approximately 2,000 Chinese characters (kanji ) even just for the characters on the Jooyoo kanji [commonly used kanji ] table the nation decided on as the "standard of kanji usage for expressing in writing the national language of today in general social life." There are approximately 50,000 characters in the K'ang-hsi Dictionary that was compiled on the basis of an imperial command of Ch'ing Emperor K'ang-hsi [of China]. If we furthermore include kokuji created in Japan, variant characters, and nonstandard characters, kanji are a mysterious character system of which we do not know just how many there are. When we compare this with alphabets (even if the difference in origin called phonetic characters and ideographic characters is ignored), this overwhelming difference of quantity is not something that could simply be called the quantity of the number of characters, rather it would be safer to say it is a difference in quality.
From ancient times, the Japanese people did not have indigenous characters, so they imported kanji and Chinese words that were their combinations from China (?) and have used those in the description of the Japanese language. Unfortunately, because the Japanese were poorer at expressing pronunciation than the Chinese at the import source, multiple Chinese words that were expressed with different sounds when in the original Chinese were spoken with the same sounds, and thus they produced a mass of homonyms.
Also, while on the one hand kanji were being accepted, our ancestors invented (?) the phonetic characters called hiragana and katakana, and they used these mixed together with kanji. In this manner, the kanji/kana mixed text that is characteristic of Japan came into being.
At one time (even today it exists partially), there was the contention that we should abolish kanji, and that we should employ only kana or Romanization. Although there are some points we can nod to in this drift of argument [1], it did not reach a point where many Japanese could accept it, whether because of the quality of an inordinately large number of homonyms would create a catastrophe, or for some other reason [2].
[1] The author has had the experience of serving as a volunteer for teaching Japanese to foreigners residing in Japan. What he learned there is that kanji create a great barrier that prevents them from obtaining information. This is because although kana can be memorized, memorizing as many as 2,000 kanji is difficult, and if one cannot distinguish the radicals [of the kanji ], one cannot even search a Chinese-Japanese dictionary. The author is not a person who argues for limits on kanji, but he believes that ruby [side readings] should be attached to all kanji in public publications, such as newspapers and so on.
[2] I do not know whether or not there is a discussion about abolishing kanji in Korea, but in modern Korean, hangul, which is equivalent to Japanese kana, holds considerable importance in documents. When one looks at newspapers and the like, it is almost all hangul, except for proper nouns.
As a result, kanji/kana mixed text has been in general use up to the present, but the work of inputting this kanji/kana mixed text requires enormous effort compared to English, which comes into existence as text through typing from the keyboard without any modifications. At present, the "kana -to-kanji conversion method," which uses a keyboard into which has been carved the JIS kana arrangement and a QWERTY English letter arrangement that is almost the same as that used in the U.S., is the mainstream. However, up to reaching this point, there have been various variations, so we cannot deny the possibility that various input systems will be devised and popularized in the future.
A system using a keyboard will probably continue to be the mainstream hereafter, but as to its shape and character arrangement, there are discussions even in the U.S., so we should probably consider that there is still room for improvement. Also, even kana -to-kanji conversion systems are not perfect. Code input systems such as TUT [3], or handwriting input, voice input, and so on, based on technical innovations may be widely used.
[3] What we call a code input system is a system in which codes such as "hg" or "rbk"are assigned one by one for all characters, including kanji ; the person doing the inputting directly generates kanji/kana mixed text by typing these. There are several types of code systems. Their selling point is that if you become skilled at any of them, you can input faster than kana -to-kanji conversion, and thus among professional typists there are many people who habitually use them. The reason they have not spread into general [use] is because one goes through hardship to learn to the point where one attains skill. However, if a means such as having people memorize them together when learning kanji in school in childhood is employed, perhaps [their use] might spread.
Having said that, kana -to-kanji conversion software that changes text comprised of only kana characters into kanji/kana mixed text will probably continue to play an important role even hereafter as a necessary and indispensable component for the purpose of inputting Japanese into a computer.
The Japanese input system "VJE-Delta Ver. 2.5" of VACS Corporation, which the author works for, has been loaded onto the BTRON-specification OS "B-right/V" that Personal Media Corporation has put on sale at this time.
In this paper, I will describe an outline of a Japanese input system in its entirety, centering on the kana -to-kanji conversion system. It would be fortunate if this serves as a help in understanding the Japanese input system, which is software with a frequency of use higher than for any other kind of software application for almost all people (leaving aside the OS itself).
In this paper, I call a scheme for inputting kanji/kana mixed text through keystrokes on (not a special device such as a character tray or tablet, but rather an ordinary) keyboard a Japanese input system. Also, although we officially call the input system of each language--including [that of] Japanese--in its entirety without limitations as to devices, and so on, an Input Method, in this paper, as long as there is nothing that would disallow it, I call middleware for inputting Japanese in which mechanisms such as keyboards drivers, and so on, have been removed from that mentioned above, the Input Method (IM).
A Japanese input system, no matter what the OS, generally generates Japanese in a flow like the one below (Fig. 1).
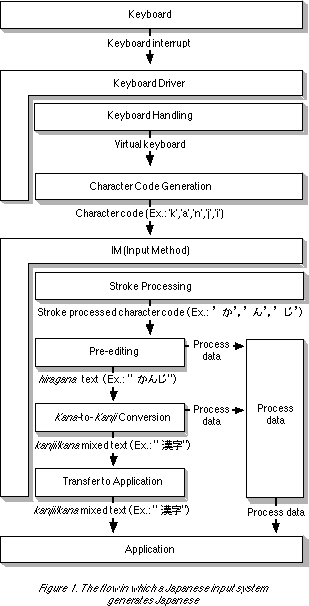
[F1] Keyboard Handling
This is a function that receives signals from a keyboard connected to a computer, generates virtual key code for the purpose of absorbing the differences in the various types of keyboard devices, and then gives notification (usually as an event).
[F2] Character Code Generation
This is a function that generates character code corresponding to the keys that were struck based on the keyboard and the keyboard status at the time the keys were struck (striking a key simultaneously with the shift key, capitals lock ON/OFF, etc.). The NICOLA arrangement (thumb shift) and so on can be viewed as one form of this function.
[F3] Stroke Processing
This is a function that generates characters corresponding to the given key input character string. What it is often used for in particular is Roman letter input; for this, it interprets the given English letter string as Roman letters and generates the corresponding kana characters. Code input systems like TUT can be viewed as a form of stroke processing.
[F4] Pre-editing
This is a function that temporarily stores a given string, or edits a stored string, prior to transferring the input string to applications (hereafter AP) such as text editors in order to perform kana -to-kanji conversion. In order to present the editing process to the person doing the inputting, we use the process presentation function described in [F7].
[F5] Kana -to-Kanji Conversion
This is a function that converts a stored hiragana text into kanji/kana mixed text. Since it is impossible to convert the hiragana text with 100% certainty into the kanji/kana mixed text the person doing the inputting desires, we present the results to the person doing the inputting using the process presentation function in [F7] for the purpose of confirming and correcting the conversion results. Furthermore, we call the character string presented to the user during processing in [F4] and [F5] the "unconfirmed character string" or the "pre-edited character string."
[F6] Transfer to the Application
This is a function that transfers the text as input to the the AP after the user certifies (directly or indirectly) that the unconfirmed character string equals the text he/she wishes to input. Generally, since an interface for transferring data between the IM and the AP is defined by the OS, we use that.
Depending on the OS, there are also cases when the interface is defined so that it is possible to transfer phrase data, reading data, and the like, in addition to sending a character code string that expresses kanji/kana mixed text.
[F7] Process Presentation
This is a function that presents to the person doing the inputting the input/conversion process in [F4] and [F5] together with data for assistance, such as lists for viewing homonyms. There are cases when it is displayed seamlessly as if it were a character string for editing in an editor (on the spot), cases when it is displayed so that it covers the character string for editing at the caret position (over the spot), and cases when it is displayed in a particular location, such as the very bottom of the screen (off the spot).
Generally speaking, [F1] and [F2] are keyboard driver roles, and [F3] and what follows serve the role of the IM, but there are slight differences depending on the OS.
Below, I shall explain how a Japanese input system is realized in [Microsoft Corporation's] MS-DOS, MS-Windows, a UNIX-type OS (X-Window), and the BTRON-specification OS. Furthermore, in addition, [Apple Computer Inc.'s] Macintosh exists as a machine/OS that is in general use. The author has heard that there is an outstanding multiple language system including a Japanese input system for the Macintosh, but because he has not studied about it, he would like to ask for the reader's understanding in omitting on this occasion.
[S1] MS-DOS/BIOS
MS-DOS is a single task, real memory OS. Hardware resources are not strictly managed and virtualized, so in order to create practical software, one must use at the same time techniques in which the machine's native Basic Input Output System (BIOS) and hardware are directly operated through the AP.
MS-DOS is the OS on which an IM (at the time it was called an FEP [Front-End Processor] ) was put to practical use for the first time (although Japanese input systems existed even prior to this, MS-DOS was the first OS on which an IM that was neither the OS nor an AP was realized as middleware); however, a unified interface for IM operations did not exist (later, the MS-KANJI interface was settled on as the industry standard specification, and the KKCFUNC that performs various services for the IM was provided).
Accordingly, in the OS, excluding portions of [F1] and [F2] that the BIOS is responsible for, the IM basically ends up taking charge of all the functions.
In addition, the AP cannot obtain the kanji/kana mixed text as anything but a simple character code string, so even setting things such as input modes is impossible.
Since the OS cannot cope with multiple languages, it is impossible to import to the system IMs for use with various languages that are other than the base language of the OS, but it is possible to simultaneously run different Japanese IMs (to use DOS terminology, to "make resident") through switching by using the selkkc command.
Furthermore, in order to provide to the AP greater main memory space, which is limited to 640 kilobytes, the IM itself is required to run on top of either the EMS or XMS memory management system, which necessitates troublesome procedures.
[S2] MS-Windows IME
MS-Windows is a multitask, multiple window OS with a virtual memory organization; common IM interfaces have been prepared in the Chinese, Japanese, Korean, and Taiwanese versions of MS-Windows98/NT.
In this OS, all events and data, including keyboard keystroke data and IM status data, are sent as window messages to the window with the keyboard focus. The AP can also interpret given messages by itself, and it can also have the appropriate processing carried out on them by transferring those system messages to the system default message handlers. Through this organization, everything from APs where it is all right if they can simply input text to APs where there is coordination at a high level with the IM can broadly bask in the benefits of the IM.
[F1] and [F2] are the duties of the keyboard driver, from [F3] to [F7] are the duties of the IM. However, concerning [F7], the OS is made up so that it is possible to implement that function by means of the AP processing messages, and thus data exchange rules for that purpose have been decided.
Moreover, the AP can obtain reading data and phrase data from the IM in addition to kanji/kana mixed text, and it is also possible to easily set general input modes, and so on.
Although it is possible to run and use multiple IMs through dynamic switching, at the present point in time (in spite of the fact that the interfaces are unified) it is not possible to import IMs for use with various languages that are other than the base language of the OS.
[S3] UNIX/X-Window
In the case of UNIX and OSs similar to it, although IM interfaces are not prepared in the basic system [software], the X-Window window system, which is the de facto standard with UNIX-types OSs, provides IM interfaces called XIM (however, in the case of UNIX, due to historical circumstances, the situation is that IM interfaces outside of XIM exist in parallel, which is a point that makes UNIX different from other OSs).
A feature of X-Window that can be mentioned is that the window system itself is network compatible. For that reason, there are also cases when the individual parts from [F3] to [F6] are provided as separate modules (in this connection, in VJE-Delta for Linux/FreeBSD, the functions of [F5] are made up as a separate module, and they can be made to run on other machines connected to the network).
Coordination with the IM is carried out through the X-Window event system and callback function; it is flexible to the same degree as MS-Windows.
However, the resultant data are only kanji/kana mixed text; reading data, phrase data, and so on, cannot be obtained, and the setting of such things as the input mode also cannot be carried out.
Although it is possible to use multiple Japanese IMs and IMs for various languages in the same system, normally, they cannot be used by dynamically switching them inside a single AP.
[S4] BTRON
In BTRON, an IM specification called TIPs [Text Input Primitives] is prescribed.
The keyboard driver is in charge of [F1] and [F2], and the IM is in charge of from [F3] to [F6]. As for [F7], it is completely the responsibility of the AP; TIPs do not possess any display function whatsoever.
TIPs are different from MS-Windows and X-Window; they are completely detached from the OS event system. Accordingly, when using TIPs, the AP must explicitly pass to the TIPs the key events/character codes that are obtained as the results of processing in [F1], [F2].
Since the responsibility on the side of the AP is great compared to other systems, standard application libraries, such as an event processing library, text input processing library, and so on have been prepared to compensate for this [4].
[4] It is something that can be said of TRON-APIs [Application Program Interfaces] in general, but in TRON, the APIs are arranged at the minimum level necessary compared to other OSs. This is a question of design philosophy; it is not a matter of which is good or bad. However, personally, I think TRON-APIs, where functions are compactly arranged and there is a high degree of freedom for creating APs, are desirable.
The AP can obtain reading data and phrase data from the IM in addition to kanji/kana mixed text, and IM controls such as input modes and so on are also possible.
Furthermore, according to the BTRON1 puroguraminngu hyoojun handobukku [BTRON1 programming standard handbook], TIPs form a specification for which no more than one can exist in the system, but it seems like there will be an expansion on this point to match with multilingual compatibility in the future.
In the previous section, I discussed the broad flow of a Japanese input system. However, if I do not describe "kana -to-kanji conversion" further, there will probably nothing of interest to the reader. On the other hand, in a description of "kana -to-kanji conversion processing," the reader needs an understanding of the grammatical structure of the Japanese language, which is the object of that processing.
Accordingly, in this section, I will briefly discuss the grammatical structure of a Japanese sentence. I would like to ask you to think of this as a review of Japanese, so please bear with me for a moment.
Japanese is composed with lines of phrase. What we call a phrase is "the smallest unit at which a sentence is punctuated without being unnatural in terms of meaning or pronunciation." In order to distinguish [phrases], we add the terminal particle (ne), and then all we do is look for places that have not become unnatural. For example, kotoshi-wa (ne) reika-ni (ne) nari-sou-desu (ne) 'It seems like this year we'll have a cold summer' (Fig. 2a).
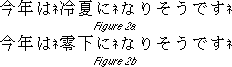
[Translator's Note] The word reika 'cold summer' above is not listed in dictionaries, but it is pronounced the same as reika 'below freezing'. Therefore, it would seem the sentence is "semantically unnatural" --to use the author's words--and should be corrected so as to read, 'This year it seems like it will go below freezing' [Fig. 2b].
Phrases can be classified into the following five types in accordance with the semantic role they play in a sentence (Fig. 3).

Also, a phrase can be divided into a chain of an independent part and an attached word; the independent part can be divided into an independent word and affixes (prefixes and suffixes) to its front and rear (Fig. 4).

A word refers to the words and affixes that are obtained as the result of breaking [dividing] phrases (properly speaking, an affix is not a word, in this paper it is included with words for the sake of convenience).
Words are classified into several parts of speech in accordance with their grammatical properties.
I give the classification of the parts of speech in the Table [below]. The black dot attached to the beginning of a line denotes a part of speech.
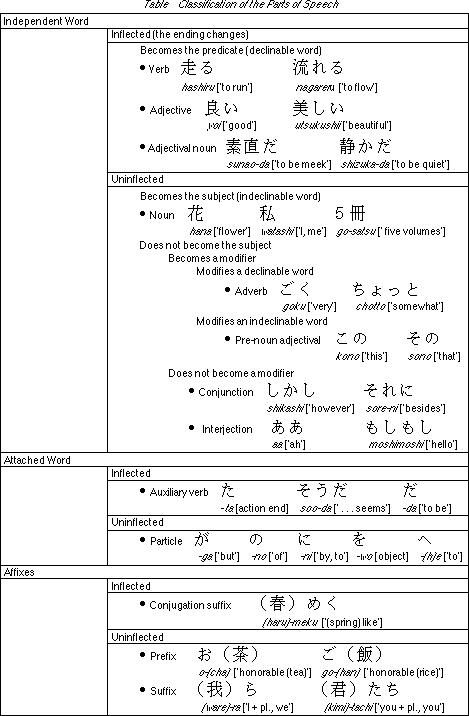
Finally, among the parts of speech in this table, it is possible to separate the ones that are inflected into a stem (a front part that does not change) and a inflectional ending [5]. We call the minimum units possessing meaning as word fragments or words that are obtained as a result of this separation morphemes.
[5] However, as for the handling of the stems for one-step (type two) verbs, such as kiru 'to wear' or neru 'to sleep', in contrast to general grammar which treats them as not having stems, there are many instances of ki- and ne- being treated as stems in kana -to-kanji conversion.
Above I have briefly described the grammar of spoken Japanese. Moreover, for those who are inclined to desire to learn further details, I would like you to refer to References Documents [1] and [2] [listed at the end of this paper].
A Scheme for Kana -to-Kanji Conversion
The core of a Japanese input system is "kana -to-kanji conversion," which generates kanji/kana mixed text from hiragana text [6]. In the manner that it is also commonly called the "conversion engine," kana -to-kanji conversion is the essential function a Japanese input system, and it is also the place where each IM vendor wages cutthroat competition.
[6] The history of research into "kana -to-kanji conversion," which is the core function in a Japanese input system, is exceptionally old; it has been carried out since the latter half of the 1960s. Since this was an in which age in which it is uncertain whether not just kanji codes, but even ASCII codes were established, it is without a doubt that it was science fiction-like research at the time. What these research results reached fruition in and were commercialized in was the "JW-10" Japanese-language word processor that was put on sale by Toshiba Corp. at the the end of 1978. Priced at 6.3 million yen at the time, the JW-10 was a thing the size of a desktop space, or rather a desk as is was the machine.
The internal processing can generally be divided into:
morpheme analysis
syntactic/semantic analysis
Recently, what is called
context analysis
is also moving from the research stage to practical use.
In addition, in performing the above-mentioned processing, various data concerning language must be stored, and in order to also fetch those data
dictionary search/update
are also required functions.
Furthermore, in the implementation phase,
real-time performance
memory efficiency
are also important elements for the conversion engine. For example, a conversion engine that makes the user wait several seconds even though the precision is good will not be used, and one that uses up to so much memory that the application cannot run is putting the cart before the horse. A compact conversion engine that produces results on the order of from 100 to 200 milliseconds and does not put pressure on the computer's resources is called for.
Morpheme Analysis
Extracting the phrases, words, and morphemes included in the given hiragana text and generating a line of several candidate phrases is morpheme analysis [7].
[7] This term includes everything: cases in which morpheme analysis is mentioned in general; cases of the language of the given text, and also cases of Japanese; cases of kanji/kana mixed text or hiragana text; or furthermore cases in which the phrase breaks are given beforehand, and cases when they are not. Accordingly, when applied to kana -to-kanji conversion, we should strictly say "morpheme analysis of Japanese hiragana text written without spacing," but in this paper I am using the term morpheme analysis with the above-mentioned meaning. However, recently, since users employing Roman letter input have increased, and also because there has been an increase in instances of English (English words) being described as is in Japanese, it is becoming "morpheme analysis of English-mixed Japanese Roman letter text written without spacing."
As for morpheme analysis in kana -to-kanji conversion, because there are no clear phrase breaks in the given text [8], the conversion engine itself must find the phrase breaks, which is the most important clue for analysis; moreover, because the text is formed only with hiragana and clues for locating the phrase breaks are scant, analysis is difficult.
[8] Although it may seem like going against the times, the author has had occasion to think how would it be if people inputting clearly inserted breaks between syllables also in Japanese. Although this would require a little time when inputting, not only would the precision of conversion improve, but I think it would also be very helpful as original data for editing, search, and processing various languages afterward. Of course, since it would probably be exceedingly difficult to accept this [if it was done] by using the same spaces as English, we would decide codes that serve as "space characters without any width"--which do not have width at output time, and which appear to the viewing eye as if there are no breaks--with those codes we would make breaks.
Accordingly, as a result of long years of research, techniques called the N phrase longest match method and the minimum cost method were devised, and by combining these together, analysis to a certain extent became possible [9].
[9] As there has even been a case of a certain IM vendor crying out in its publicity for its IM that "it is based on the minimum cost method," there is also an inclination toward the misunderstanding that the N phrase longest match method and the minimum cost method are competing technologies, and that moreover the minimum cost method is superior. However, this is a mistake; normally, we make the N phrase longest match method the base, and we employ the minimum cost method in order to compensate for its weaknesses. Of course, even that IM vendor's IM was structured like that (a snake's path [is taken] by a snake; as to what kind of logic they are using, it is possible to almost guess even without reverse engineering). Although it is slightly off the topic, as for expressions that echo "the _ _ technology that our company is proud of," which often come out in CM and publicity, there is a great possibility that it has become a mere marketing term, as [is the case] with "neuro" and "fuzzy." Therefore, listen to it as something that is half true, and there will not be any mistakes (and even at our company, which is saying this, the truth is that things seem to be like this, but . . . )
Below, I will explain in order three techniques: the longest match method, which could also be called the progenitor of the N phrase longest match method; the N phrase longest match method; and the minimum cost method.
[A1] Longest Match Method
The longest match method is what was first thought up as a technique for Japanese morpheme analysis. This is a technique in which the longest phrase from the beginning of the given text is cut out; the technique is based on the empirical rule that the longer the length of a phrase, the closer it will (probably) be to the correct breaks. As a result of the fact that a certain degree of conversion precision to a simple percentage (in other words, does not require computing power) can be obtained, it was often used initially, and even today, depending on the use, it is sufficient for practical use.
This technique walks through the stages of finding the longest thing in the independent word (or the stem of the inflected word); if the word obtained inflects, judges the inflectional ending of the following word; and furthermore judges (the string of) the attached word of the following word.
For example, let's try applying this technique to (part of) the text written "sakanai " [in hiragana ].
First, we look up "sakanai " in the dictionary. However, since there is no word that matches, we search the dictionary for "sakana " in which we have shortened by one character. Doing that we obtain [the Chinese character for] 'fish' (noun), but since it is impossible to attach "i " to the end of a noun, this is rejected. When we search the dictionary for "saka " by shortening further, we obtain [the Chinese character for] 'slope' (noun), but since it is also impossible to attach the following "nai ," this is rejected. Finally, we when we search the dictionary for "sa ," we obtain [the Chinese character for] 'to bloom' (a ka line five-step verb). Since verbs are inflected, we judge whether or not the following "kanai " matches an inflectional ending; because "ka " matches the imperfect form, we make this the verb ending; and furthermore it is possible to attach the following "nai " also to the imperfect form of a verb. With this we the [kanji/kana mixed text] text "sakanai " '. . . does not bloom'.
[A2] N Phrase Longest Match Method
When we break the text "karenihatarakikakeru " [' . . . go to work on (appeal to) him'] with the longest match method, we get "kareniha / tara . . . ," and then things do not go well. Accordingly, the N phrase longest match method is a technique in which after we obtain "kareniha " with the longest match method, we search again also for phrases that are shorter than the longest phrase. We searching in the same manner as the N phrase part through the following of several phrases that are obtained. Finally, we select the pattern where the total length of the N-piece phrase is the longest.
Using the above-mentioned text as an example, when we analyze with the 2-phrase longest match method, which is used comparatively often among N phrase longest match methods, we obtain two candidates:
"kareniha / tara / kikakeru "
"kareni / hatarakikakeru "
Since between these the length of the 2-phrase portion is longer for "kareni / hatarakikakeru ," this is selected.
[A3] Minimum Cost Method
In contrast to the N phrase longest match method (including the longest match method) being something based on the empirical rule that the longer the length of a phrase the closer it will (probably) be to the correct breaks, the minimum cost method is a technique based on the empirical rule that the relationship of the adjoining parts of speech that is plausible will (probably) be close to the correct breaks. Specifically, this is logic in which we use combinations of phrase breaks with the lowest cost by calculating the cost of the links between between each part of speech based conditions such as: since a pattern in which a noun comes after a noun is rare, we give it a high cost (penalty), and since there are many examples of text in which a particle follows a noun, we give it a low cost.
Below, I will show what happens when we apply the minimum cost method to the text "yamanouenihanagasaita " ['flowers bloomed on the mountain'] (incidentally, this text is famous for being text that is impossible to analyze with the 2-phrase longest match method).
We fix the costs in the following manner (Fig. 5):

When we make the following four candidates (Fig. 6),

the following cost calculations are then made (Fig. 7)
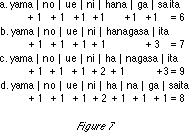
and then a. which has the lowest cost is used.
However, in regard to the combinations of the parts of speech, [there are considerations such as] how one gives them costs, and also since it will take a great amount of time if we simplistically calculate all combinations, allowances for processing in order to remove from the objects [of processing] patterns that do not even seem possible (for this, the longest match method is used a lot), etc., so even though we call it in short the minimum cost method, there can be various variations of it.
Above, by taking a look at the N phrase longest match method and the minimum cost method, which are two techniques of morpheme analysis, I have introduced an outline of morpheme analysis.
In summary, in morpheme analysis, there are the techniques called the N phrase longest match method and the minimum cost method, and since they are both based on empirical rules in Japanese text, they cannot peform completely correct analyses, and thus it comes about that the joint use of the two techniques is typical.
Furthermore, in the VJE-Delta [version] that has been loaded onto B-right/V, we jointly use the 3-phrase longest match method and the minimum cost method.
Syntactic/Semantic Analysis
Investigating whether the phrase row (of several candidates) obtained with morpheme analysis is grammatically correct or not (syntactic analysis), and further, investigating the meaning of the text (semantic analysis), and obtaining an appropriate phrase line and its homonyms is syntactic/semantic analysis.
As a technique for syntactic/semantic analysis, there is a technique based on "case frames," which VJE-Delta was the earliest to adopt among commercial IMs, and which other companies are now following in its wake.
This technique analyzes syntax based on "case grammar," which lays stress on the meaning of words rather than their order; it is something that arranges and integrates the semantic data obtained as a result of analysis with "frame theory," which is a technique of knowledge representation in artificial intelligence technology.
Specifically, in regard to declinable words that become predicates (verbs, etc.), we place in memory inside a dictionary indeclinable words (nouns) related to those declinable plus case data (particles) that show the relationship between indeclinable words and declinable words. At such time, because memory space will be wasted if we end up interrelating indeclinable words one by one to declinable words one by one, in the manner that a cherry blossom is a flower, and a flower is a plant, we position indeclinable words inside a hierarchical structure of abstract concepts, and then we interrelate the declinable words to those abstract concepts. We call this "example data."
If we do things in this manner in advance, for text such as "inuwokau " [' . . . raise(s)/buy(s) a dog'], we can obtain text such as "inu-wo kau " [' . . . raise(s) a dog'], since a dog can be raised as a pet; and in the case of "pettoshoppudeinuwokau ," we can obtain the text "pettoshoppu-de inu-wo kau " [' . . . buy(s) a dog in a pet shop'] by combining the example data "one can buy (an arbitrary thing) in a store" with the frame knowledge that "a shop is a kind of store" [10].
[10] Steadfast example data collection is indispensable for this technique. This is because, for example, a "penguin does not fly," although a "hard disk flies."
Context Analysis
This is an area that each IM vendor has recently begun to set its sights on (in our company also this area is still in the research stage).
For example, when we are given the text "saigonosoosya," if it is in a sports article, it would probably be "saigo-no soosya " ['the last runner']; and if it is in an article about show business, it would probably become "saigo-no soosya " ['the last player/instrumentalist'].
This type of processing in fact has some points that no matter what are difficult to do just with the conversion engine. Generally speaking, by predicting that there probably will not be any instances in which we write side by side two [pieces of] text with completely different contents, the only method to adopt is one in which go forward accumulating the context data of text that are given one after another. However, in order for it to perform more accurately, the whole system needs improvements, including an interface through which the AP notifies the conversion engine of the text the front and rear of the caret position.
Dictionary
Although it is a part that is not very conspicuous, in fact the precision of conversion is most greatly controlled by the contents of the dictionary. This is because if a word not in the dictionary is given, naturally it will be impossible to analyze it, and, furthermore, because it will also lead to the production of an obstacle in the analysis of the following text. There are often cases of absurd misconversions being pointed out in articles that compare IMs, but in almost all these cases, there are many resulting from the fact that the appropriate word has not been recorded in the dictionary. Having said that, if one asks if it is all right to recklessly increase the vocabulary items, words must be increased very cautiously, because the more words increase the more dictionary search speed falls off, and also because there are instances when, depending on the word, it ends up causing an impossible misconversion.
In our company, when we record VJE-Delta vocabulary, we are making efforts to raise the precision of conversion by carrying out surveys of various documents, and scrupulously collecting words, including even up to their frequency of use.
Large Character Set Support
The VJE-Delta that has been loaded onto B-right/V employs Shift-JIS as a base, and, in addition to this, it uses an internal code that makes possible the representation of arbitrary 2-byte codes and 4-byte codes. This is a port of a VJE that was reorganized for accommodating ISO-10646 UCS2 (2 byte) and UCS4 (4 byte) when we made VJE compatible with Unicode. Because it is not pure TRON code, it cannot cope with the "unlimited code" that Project Leader Sakamura talks about, but an increase on the order of 1 million units is not disheartening. I would definitely like you to take a look at its capabilities when 3B/V currently under development at Personal Media Corporation has been put on sale.
I have been describing in general terms a scheme for a Japanese input system. However, as long as I am contributing to TRONWARE, I would like to mention places where there are expectations from the standpoint of the IM vendor concerning the Japanese input system interface in [the] BTRON (-specification OS).
All recent major OSs are solely those that have been developed in the U.S. These normally adopt a policy of prescribing a consistent IM interface from the macro viewpoint of internationalization. That in itself is good (rather, if that was not the case, there would be difficulties), but at such time, the circumstances of each country are in the end liable to be ignored or underestimated, and so there are also many things we are dissatisfied with as IM vendors.
Accordingly, for BTRON, which aims at becoming a multilingual OS in the true sense in the future, I would like internationalized framework creation carried out after giving sufficient consideration to the circumstances of each country's language without treading down this rut.
Abundant Data Exchange Framework
For data exchange between the IM and AP, the interfaces are generally prescribed in accordance with the OS. When the interfaces are weak ones, the functions of the IM itself ultimately become limited.
As was mentioned above, the IM, in the process up to outputting kanji/kana mixed text, is generating reading data, phrase data, part of speech data, and so on. These abundant language data that the IM possesses end up being discarded simultaneously with the end of of conversion.
Also, if graphics such as logo marks and the like are stored for future use in the dictionary in the same manner as character strings, it is possible to easily input these during the input process of the IM, but regrettably it is impossible to hand those graphic data over to the AP. In particular, because it is stated in TRON that user defined characters are rejected, it seems like graphic transmission to substitute for that will be required.
TRON is prepared with a general-purpose data exchange framework called TAD [TRON Application Data-bus]. If TAD is used in data exchange between the IM and the AP, and, in addition, if that is done by defining a tag for the data the IM generates, then it will be possible to transfer those data to the AP (leaving aside the question of whether or not those will be used by the AP).
And then, it is desirable to also have a mechanism that can do things such as sending notification from the AP to the IM about the text to the front and rear in order for the IM to understand the context, and in input fields such as names and addresses, sending notification to the IM of those field attributes.
Adjustment of the Input Framework
A Japanese input system passes through the stages of keyboard handling, character code generation, stroke processing, pre-editing, and kana -to-kanji conversion.
These functions are embedded in either the keyboard driver or inside the IM; it is impossible to easily modify or extend these functions externally on almost all OSs.
From the TRON standpoint, it may not be desirable for divergent input methods to exist in parallel, but as long as there are NICOLA enthusiasts and TUT enthusiasts, I think we should open the door widely also to these users.
In that regard, it is desirable to precisely divided into small parts the above-mentioned various functions, and to prepare a structure in which it is possible to easily replace them.
Adjustment of TAD Operation Functions
Although it is not directly related to the IM, I would like to say a word from the programmer's standpoint.
TAD (including character strings) is good as rules for data exchange, but although these operations are better than Unicode with composite characters, it is more troublesome than EUC or Shift-JIS.
Project Leader Sakamura's saying that "In TRON, because there is TAD . . . " is true as a general theory, but from the side of those concretely implementing it, TAD is troublesome, and thus there is the fear that only the "casual multilingual plane" will be made the target of operations, and that afterwards it will end up becoming "other countries, sorry."
At the least, it is desirable to complete a TAD operations library with the simplicity of C string functions that makes it possible to precisely operate the character set.
[1] Denshi tuushin gakkai: Nihongo joohoo shori [Japanese information processing], The Institute of Electronics, Information, and Communications Engineers
[2] Watanabe Masakazu: Kyooshi-no-tame-no koogo bunpoo [Masakazu Watanabe: Spoken grammar for teachers], Yubun Shoin
[3] Nishikimi Mikiko, Takahashi Naoto, Tomura Satoshi, Handa Kenichi, Kuwari Seiji, Mukaigawa Shinichi, Yoshida Tomoko: Maruchiringaru kankyoo-no jitugen [Mikiko Nishikimi, Naohito Takahashi, Satoshi Tomura, Kenichi Handa, Seiji Kuwari, Shinichi Mukaigawa, Tomoko Yoshida: Realization of a multilingual environment], Prentice Hall Japan
[4] Itoo Hidetoshi: Kanji bunka-to konpyu--ta [Hidetoshi Ito: Chinese character culture and computers], Chuokoron-sha
[5] Sasaki Mizue: Gaikokugo-toshite-no Nihongo [Mizue Sasaki: Japanese as a foreign language], Kodansha
[6] Nagao Makoto hen: Gengo-no kikai shori [Makoto Nagao edited: machine processing of language], Sanseido
[1] Wa-puro ichigooki-ni kaketa otoko-no sensoo [The war a man waged on word processor number one]:
http://www.glocom.ac.jp/Personnel/Furuse/archive/doc/shincho45_9212.html
[2] Tensai Kurihara Toshihiko-no gyooseki [The achievements of genius Toshihiko Kurihara]:
http://www.glocom.ac.jp/Personnel/Furuse/archive/doc/shincho45_9202.html
B-right/V is a registered trademark of Personal Media Corporation
The above information appeared in the article "B-right/V Quick Reference" on pages 54-62 of Vol. 53 of TRONWARE . It was translated and loaded onto this web page with the permission of Personal Media Corporation.
Copyright © 1998 Personal Media Corporation
Copyright © 1998 Sakamura Laboratory, University Museum, University of Tokyo