
Today I would like to review once again what the TRON Project is doing in regard to Japanese-language processing. Beginning with a historical view of Japanese-language processing, I would like to talk about the number of Chinese characters (kanji ), the present state of codes, and the TRON concept in regard to these.
Looked at historically, about 20 years has elapsed since it has become possible to process the Japanese language on a computer. The first Japanese-language word processor is said to be the Toshiba JW-10, which appeared in the fall of 1978. It was an extremely expensive thing priced at more than 6 million yen; today it has come about that we can buy this for less than one-hundredth that price. Together with that, right in this month of January in 1978, what we call the JIS kanji code was established. Up until that time, kanji had not been included in JIS standards; however, beginning here JIS became concerned [with kanji ]. What was announced at that time is the standard to which the number [JIS] C 6226-1978 was attached. This has been revised several times up to the present; today the standard we call JIS X 0208-1997 has appeared as the fourth version (Fig. 1).

Well, over these 20 years the computer has achieved radical progress. Both in terms of speed and capacity, it has attained several hundred times the performance, and even the price has come down to one several hundredth. In contrast to this, when we ask how the handling of the Japanese language really turned out, after the passage of 20 years, the situation is that the number of kanji has not increased. The number of kanji for the very first general computer that appeared was 6,349; today it is 6,355 characters. Nineteen seventy-eight, '83, '90, '97--in spite of the fact that JIS has been revised, there has been almost no increase in the number [of kanji ]. Well then, if one asks just exactly what did JIS revise, all they did was substitute locations. What has happened is that they have done things such as putting things that were originally in [JIS] level 1 into [JIS] level 2. As a result of this, naturally confusion has arisen. On the basis of what intentions this is done, even I do not understand.
With this, naturally the number [of kanji ] is insufficient; although 5,801 auxiliary kanji were created when JIS X 0212-1990 appeared, there is no computer that can directly handle these outside of BTRON. If you ask what computer types other than BTRON do [with these characters], they are set up so as to use them after registering them as user-defined characters.
By the way, as to the number of kanji does everyone here know about how many there are? (Fig.2) Although various numbers have been mentioned, there are 1,006 kanji learned in primary school called kyooiku kanji [education kanji ], and there are the 1,945 characters of the jooyoo kanji [commonly used kanji ]. And then there are 284 characters called jinmeiyoo kanji [kanji for use in personal names] that can be used for registering names in family registers. This is the standard for the amount of characters to be used in ordinary social life, but then, if we ask about how many kanji are there outside of these basic ones, in the Xinhua Zidian, which is the standard dictionary of modern China, there are 10,000 characters, including about 5,000 Chinese characters for common use. And then, in the K'ang-hsi Dictionary, which appeared in 1716 and could also be called the "roots" of Chinese character dictionaries, there are 47,000 characters. In the Hanyu Da-Zidian of China that appeared in 1986, there are 56,000 characters. And then in the Zhunghua Jihai, the largest dictionary in China that appeared in 1994, there are 85,000 characters. There are about this many. Furthermore, there are also many characters that are not listed in dictionaries, kanji used in personal names and place names; these are kokuji [kanji created in Japan] and things called variants [alternative forms of characters], etc.When all of these are combined together, it is said that there are generally between 80,000~100,000 characters. However, as to the question of how many kanji there are in the end, the fact is that we do not know for sure. Also, I will talk about this a little later, but as for what we call kanji in China, Japan, and Korea, the shapes of them vary slightly with each other. Therefore, if we combine all of these together, the situation is that there are several hundred thousand kanji.

In addition to what originates from those facts, if one asks exactly what is the problem, this is difficult [to answer]. To tell you the truth, even explaining what the problem is is rather awful. There are also technical, political, and personal problems, so the story is complex. However, in the end, what can absolutely be said is that the number of kanji that can be processed on a computer is small. The 6,355 characters of JIS X0208 are [too] few no matter who looks at it for whatever purpose. Although people are talking about the planned addition of 5,000 characters with JIS levels 3 and 4, this is like the "spinkling of water over thirsty soil."
Next I would like to talk about Unicode. This is in fact the same as the 10646-1 [standard] of the International Organization for Standardization (ISO), and it encompasses big problems. The thing that is the biggest problem is what is called unification; kanji with similar shapes are encoded as one character by lumping together China, Japan, and Korea. If you ask why they are doing such a thing, it is because creating Chinese, Japanese, and Korean kanji separately involves costs. Thus they say lump them all together. This is the high-handed logic of people who do not use kanji , but the fact of the matter was that they want to develop them all together for reasons based on so-called marketing [logic]. In other words, in the beginning, there wasn't [anything to do with] an international standard or anything else. However, this is called a de facto standard; in the end if everyone buys it, it is meaningless to make an international standard out of the things that are not used. Although there are also some differences on fine points, the situation is that Unicode in fact ended up becoming an ISO standard.
What's another problem with that is, to put it simply, is that although all of the JIS code has been entered in Unicode, it has ended up being shuffled. They didn't enter the JIS code as is, rather it has been entered in a disjointed fashion. That is to say, there is absolutely no compatibility. Japanese only use Japanese kanji, Chinese only Chinese kanji, and Koreans only use Korean kanji. Therefore, people say there isn't any problem, is there? The JIS kanji have all been entered, haven't they? However, that is very distressing. No matter what is said about JIS, it is in fact [a standard] used in Japan at present. Why is it that only ASCII [Amercian Standard Code for Information Interchange] code has been entered as is, but JIS kanji are all over the place? The problems with Unicode are set in relief when we look at XKP [eXtended Kanji Processing] [standard] (Fig. 3). What is called XKP is a user-defined character system for situations when there is trouble with kanji for personal names and the like not appearing when trying to use [Microsoft Corp.'s] Windows-NT in municipalities and the like. Because variant characters have been lumped together in Unicode, personal names cannot accurately appear. Therefore, attempting to manage that portion as user-defined characters is the basic way of thinking. The very release of this type of thing proves the inadequacy of Unicode. Moreover, even when [considering] XKP [itself], a problem also appears when one considers communications via computer. When transmitting user-defined characters to one's opposite, they are thinking of preparing a server to manage user-defined characters with XKP and transferring user-defined charcters of whichever font to the opposite, but a fundamental problem is that searching ends up going amiss because the receiver becomes unable to judge whether the user-defined characters that have been registered all over the place are the same or different.

For example, the "yoshi" of Mr. Yoshimeki '![]() ' is not the "yoshi"
written with the character for 'warrior' [forming the top half,
' is not the "yoshi"
written with the character for 'warrior' [forming the top half, ![]() ], rather it is the "yoshi" written with the character for
'earth' [forming the top half,
], rather it is the "yoshi" written with the character for
'earth' [forming the top half, ![]() ]; it is impossible
to express in writing [this second] "yoshi" with either JIS code
or Unicode. For the character for "bone" also, it is impossible
to distinguish the character used in China from the character used in Japan,
even though they are different. If you ask why is it troublesome if we cannot
distinguish this, it is because we cannot even write a sentence that states
"the character for bone in China '
]; it is impossible
to express in writing [this second] "yoshi" with either JIS code
or Unicode. For the character for "bone" also, it is impossible
to distinguish the character used in China from the character used in Japan,
even though they are different. If you ask why is it troublesome if we cannot
distinguish this, it is because we cannot even write a sentence that states
"the character for bone in China '![]() ' is different
from the character for bone in Japan '
' is different
from the character for bone in Japan '![]() '." I ask
myself why is it they don't understand a basic thing like this, but it is
impossible to get some of the people doing Unicode and JIS code to understand.
In any case, if characters exist, all we need is a method in which procedures
are laid down in advanced so that they can all be registered. If only the
shape of a character is recognized to be different, and even if it's only
the proposal of just one person, for instance, it's fine to register it.
Something to that extent is allowable given the capabilities today's computers
possess. That's because compared to motion picture data, character data
and the like is lighter by far. Anyway, making it possible so that any character
whatsoever can be expressed in writing is the TRON way of thinking (Fig.
4).
'." I ask
myself why is it they don't understand a basic thing like this, but it is
impossible to get some of the people doing Unicode and JIS code to understand.
In any case, if characters exist, all we need is a method in which procedures
are laid down in advanced so that they can all be registered. If only the
shape of a character is recognized to be different, and even if it's only
the proposal of just one person, for instance, it's fine to register it.
Something to that extent is allowable given the capabilities today's computers
possess. That's because compared to motion picture data, character data
and the like is lighter by far. Anyway, making it possible so that any character
whatsoever can be expressed in writing is the TRON way of thinking (Fig.
4).

TRON code is 16-bit code. However, because it is a code system that possesses multiple 48,000-character character planes through a switching system, not only is there in actuality no limit to the number of characters that can be accommodated, but resource efficiency is very good. And then, it has no user-defined characters. Of course, when characters are lacking, a database is made to register them, and we are planning the creation of a center for that purpose. Moreover, character code that is considered necessary will be registered and added in a timely manner. Limitations will not be attached. Computers today differ with the computers of 20 or 30 years ago, which had limitations to their resources; a single personal computer today boasts a high level of performance that even the computers throughout the world at that time combined together couldn't achieve. Therefore, all we have to do is register and add in a timely manner characters thought to be necessary, and then make those data public. As for symbol types, all we have to do is enter them into documents as figures [graphics]. To put it in an extreme way, it would be all right even if all the Japanese people think up kanji anew and register them. That's because there is that much room. Although it's ironic to say this, it is impossible to print the Unicode standard book with a Unicode machine. In what's called version 1 of the Unicode standard book, it is explained that the kanji of China, Japan, and Korea were unified in such and such manner. However, BTRON is the only computer that can print it.
As for another thing in distinguishing characters, there is something
based on what I call "character sense." The differences in the
design of typefaces are things we handle on a different level as font [stylistic]
differences; however, characters that we sense at a glance are different
must all be distinguished. I call those kinds of differences character sense.
For example, the character forms in circulation and the way of thinking
about kanji has changed from the Heian, Edo, Meiji, and Taisho periods
[of Japanese history]. Of course, the roots of all of these are China, it
should be said. However, they have been slowly changing ever since their
importation to Japan. We will properly amass those types of data as a character
sense database and make them public. If we accurately make a database, we
can support all of [kana -to-kanji ] conversion and search,
and we can also do narrowing down data searches based on a specific purpose.
And then, by making it reflect regional differences it will also become
possible to deal [with characters] by distinguishing the differences among
the characters of China, Japan, and Korea. If we take the character '![]() ' [yoshi] as an example (Fig. 5) of a change in the shape of a character
through the ages, then traditionally it is '
' [yoshi] as an example (Fig. 5) of a change in the shape of a character
through the ages, then traditionally it is '![]() '. When we look
it up up in the K'ang-hsi Dictionary, although it appears in the form of
'
'. When we look
it up up in the K'ang-hsi Dictionary, although it appears in the form of
'![]() ', in Japan it was '
', in Japan it was '![]() ' right up until
the beginning of the beginning of the war. I will say this over and over
again, but if we lack the characters, we can't even write a sentence like
that. For instance, if a person in the faculty of literature intends to
do research on the character '
' right up until
the beginning of the beginning of the war. I will say this over and over
again, but if we lack the characters, we can't even write a sentence like
that. For instance, if a person in the faculty of literature intends to
do research on the character '![]() ' for a graduation
thesis, what is he or she to do? In the present, which is the golden age
of word processing, we end up in a situation where we say as far as those
people are concerned, isn't writing it by hand the only thing they can do?
' for a graduation
thesis, what is he or she to do? In the present, which is the golden age
of word processing, we end up in a situation where we say as far as those
people are concerned, isn't writing it by hand the only thing they can do?

In addition, we also hear the opinion that it's not a good thing just to increase the number of characters. If we increase them randomly, the user will be all the more confused. However, if one is allowed to make a rebuttal, the biggest problem is a situation in which a character does not exist. Moreover, this doesn't mean I'm saying use anything and everything. Having many kanji entered into a computer is for sure a different problem from using them. It is also possible to prepare a kana -to-kanji conversion mechanism by limiting it to a certain category. That means it is also possible to create kana -to-kanji conversion software in a way that it cannot output anything other than kyooiku kanji [education kanji ]. However, if something hasn't been entered, it doesn't appear! There is also the opinion that it is troubling as to which character variant should be used, but this also can be supported through the computer. When we unify, the distinguishing data are lost (Fig. 6).
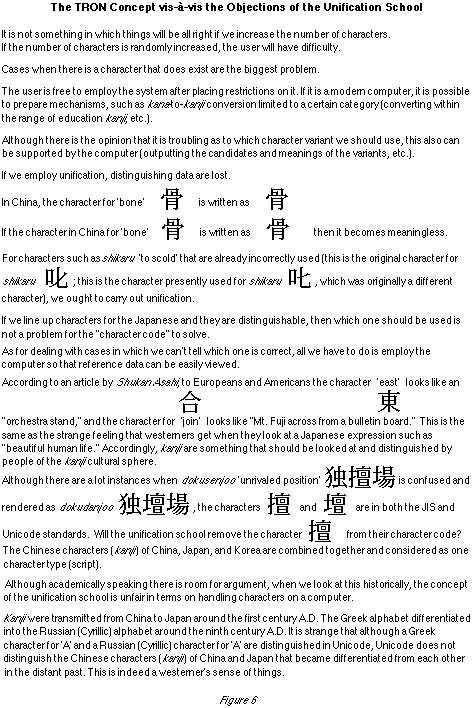
At any rate, character code must be assigned to everything. Moreover, as to kanji, I believe the people of the kanji cultural sphere should examine and distinguish them; people who don't use kanji shouldn't do the selection work. It's strange to combine together the kanji of China, Japan, and Korea and think of them as one script. Unicode distinguishes the Greek letter 'A' and the Russian [Cyrillic] letter 'A', so it is absolutely ridiculous that it doesn't distinguish Chinese and Japanese kanji. In contrast to the fact that it was around the 9th century A.D. that the Russian script differentiated from the Greek script, it was around the 1st century A.D. that kanji were transmitted from China to Japan. There are still things we don't know, and I'm not saying our database (Fig. 7) will be ready immediately. However, what I am saying is that in TRON at least we are trying to prepare the framework.

In that regard, there is a thing called Todai Mincho (GT Mincho). (Fig. 8) This is a part of the multilingual project that has been in progress since 1995 at the University of Tokyo; we are collecting 190,000 Japanese kanji and creating outline fonts. We have sorted 64,000 characters and created 51,638 characters as a Mincho font; only TRON can directly utilize this font.

The Japanese-language processing that TRON conceives, at any rate, will be made so that it can handle various kinds of kanji including Todai Mincho. And then, naturally it does not have a concept of unification. Therefore, we will make it so that the kanji of China and the kanji of Korea also can be used as is through the switching of languages.
In addition, if we list the environment that the project is aiming at, first we will make it so that it can handle historical characters. That's because the kana and manyogana of old [Japanese] documents, and at the extreme even [ancient Chinese] oracle bone characters have been entered (Fig.9). And then we will make a data search engine based on a character sense database. And then unrestricted ruby. And then reading data. This is important for EnableWare also. If we don't enter into place reading data, then we can't properly output text with a voice output device. As for the algorithms Japanese possesses, we will make it so that they can be precisely expressed. And then, because we have incorporated "Japanese katakana English" and what have you, the environment is fine tuned even for how those types of things are structured. In addition to that, we have even though about how to perform and handle the Japanese repeat symbol, the Japanese return point, and kinsoku shori [impermissible line breaks in Japanese]. Also, we have been talking a lot about a system for incorporation in electronic stationery based on simple functions. We have been thinking about using the required functions in accordance with need even for Japanese language processing.

Moreover, as I have said several times before, it is not necessary to use against one's will things one doesn't use. Being made up so that something can be used and having to possess all such things are different. First, we are now in the age of the Internet. It's no problem to enter data for keeping on a server somewhere and make it so that one calls it up when necessary. If one is connected through the network, it can be sent. As for sending via code, the transmission efficiency becomes very good, and there are no problems.
Another thing is what is called functional distribution, which is also something we have talking about from about 10 years ago. To give an example based on publishing, in the past if one wrote a manuscript, a designer did the layout, and a phototypesetter made it into neat type for you. If you ask how that is done with today's DTP (desktop publishing), you have to do it all by yourself. At such time, if the person has mastery of all the processes [involved], things are fine, but for a person who specializes in writing text to spend time with the layout is a waste. Because people who specialize in the writing of text are people who are proficient in the writing of text, I woud rather have them make the content better if they have time to pour energy into layout. I think it would fine even if we had that apportionment of roles. In TRON, I believe it's all right [if the work] of the person who writes the manuscript, the person who does the typesetting, the person who does the proofreading, and the person who does the printing are all by different people. For Japanese language processing, it is necessary to think of it by putting yourself in the position of the Japanese who will use it. By making use of modern computer science, I would like to create something that approaches the ideal even by a step for people who create text (Fig. 10).

I appreciate your listening today.
(Applause)
The above article on Japanese-language processing appeared on pages 36-44 in Vol. 50 of TRONWARE . It was translated and loaded onto this web page with the permission of Personal Media Corporation.
Copyright © 1998 Personal Media Corporation
Copyright © 1998 Sakamura Laboratory, University Museum, University of Tokyo