
As T-Engine, which is a next generation real-time system development platform, is already being marketed in more than five types of development kits, it has become possible to easily carry out programming using T-Engine. However, I wonder whether there aren't a lot of people who are bewildered by the T-Engine programming environment, which is different from both the development platforms for conventional embedded devices, and also personal computers.
Therefore, I would like to explain T-Engine programming under the title of T-Engine Programming Primer.
First, in this "The Basics," I shall explain the fundamental matters that are necessary in T-Engine programming. Next, in "Put into Practice," Mr. Koichi Sato will explain everything from obtaining a T-Engine development kit for the first time up to actually running programs.
Furthermore, in this paper, I shall proceed with the explanation while showing differences with ITRON programming based on the premise that the reader already has a basic knowledge of embedded real-time operating systems, such as ITRON, and C language.
At present, among the T-Engines that have appeared in the world, there exist two types of series: standard T-Engine and µT-Engine. First, I would like to briefly explain the differences between these two T-Engines.
Standard T-Engine
Standard T-Engine has been conceived as a platform to make possible the development of high-level information terminals and mobile devices. A 32-bit CPU loaded with a memory management unit (MMU) is used as the CPU. Also, it comes standard equipped with a liquid crystal display and a touch panel interface.
In other words, one could call this a T-Engine that can be used for carrying out development of highly functional PDAs and the like.

For example, with T-Engine/SH7727, a liquid crystal panel is attached, and operation on batteries is possible. Picture 1 is one of these onto which we have installed an optional carrying case for the work bench and rechargeable batteries; I believe it would not be strange to call it as is a PDA.
Also, T-Engine/VR5500 is standard equipped with RGB output, and it possesses an expansion bus that is PCI compatible. One gets the feeling of it no longer being a PDA, but rather something close to a personal computer.
µT-Engine
µT-Engine has been conceived with the development of embedded devices as the main target. It does not possess a liquid crystal display interface like the standard T-Engine, and the board size also has been made even smaller in scale. The CPU is 32-bit, but an MMU is not mandatory.

For example, with µT-Engine/M32014, a LAN board and a camera board are standard attachments, and thus it is possible to easily create a Web camera server (Pict. 2).
In Table 1, I have attempted to bring together the points of difference between T-Engine and µT-Engine.
|
|
||
|
|
|
|
| Board size | 75 mm x 120 mm | 60 mm x 85 mm |
| MMU | Mandatory | Optional |
| Sound CODEC | Mandatory | Optional |
| LCD panel I/F | Mandatory | Optional |
| Touch panel I/F | Mandatory | Optional |
| Card I/F | PCMCIA Type II | CF Card Type II |
| MMC card | ||
| USB Host I/F | Mandatory | Optional |
The differences between the two are mainly hardware specification differences based on the differences in development targets; the basic architecture is the same. Also, the system software that I will discuss next, if we leave aside limitations based on hardware, is basically the same thing.
Next, I shall explain the T-Engine system software.
The T-Engine software configuration is formed into the hierarchical structure in Figure 1 centering on T-Kernel. I shall now explain each layer in order.
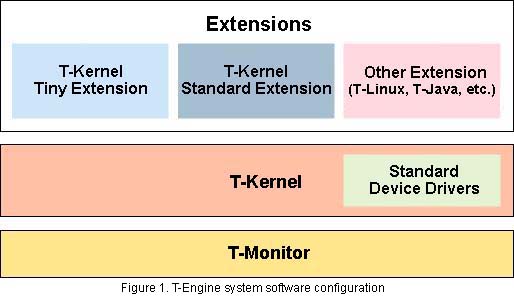
T-Monitor
T-Monitor possesses functions for hardware initialization and system startup, plus basic debugging.
When the T-Engine power source is turned on, the first thing that moves is T-Monitor. T-Monitor carries out the necessary hardware initialization, and it starts up T-Kernel. If we dare to liken it to a personal computer, we could probably say that T-Monitor plays a role that is close to the BIOS. However, it also possesses functions that are not in a personal computer's BIOS, such as debugging.
T-Kernel
What forms the core of the T-Engine system is T-Kernel.
T-Kernel is a real-time operating system that inherits ITRON technology and further strengthens it. I believe that T-Kernel is an operating system that is very easy to understand for people who already know ITRON.
Conversely, for people who know nothing other than personal computer operating systems, it might become bewildering. Real-time operating systems for embedding, such as T-Kernel and ITRON, only possess basic control functions for programs; they do not possess functions that are obvious in a personal computer operating system, such as a file system and network protocols. Normally, those are provided are as middleware.
In the configuration of a personal computer operating system, there is a thing called the microkernel; we could probably say that T-Kernel is close to that. Actually, consideration has been made for T-Kernel also being used as a microkernel, and thus subsystem management functions are furnished.
Devices Drivers
Device drivers mainly carry out control of hardware.
In ITRON, specifications concerning device drivers were not prescribed, but in T-Engine a device driver mechanism has been decided. In particular, that standard device drivers have also been prepared for standard devices is a great feature. Device drivers are placed under the management of T-Kernel, and applications call up device drivers using T-Kernel service calls.
T-Kernel Extensions
T-Kernel Extensions extend the functions of T-Kernel, and they realize the functions of higher level systems. As previously mentioned, in T-Kernel itself, functions such as a file system do not exist, but T-Kernel Extensions provide these functions.
In T-Kernel Standard Extension, even an event management function for realizing virtual memory management and a GUI has been included. Also, outside of T-Kernel Standard Extension, extensions such as T-Kernel Tiny Extension, which offers a more ITRON-like environment, T-Linux, and T-Java are also under development.
Application programs that the user creates run on top of the previously mentioned system software. Three forms as in Figure 2 can be conceived of, depending on what which layer of the system software they run on. I shall explain them in order below.
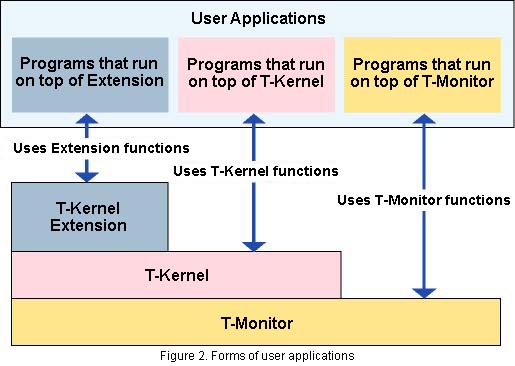
Programs that Run on T-Monitor
In T-Monitor, a program load and execute function is furnished as a debug function. By utilizing this, one can run programs on top of T-Monitor.
However, basically, one cannot utilize other system functions, such as T-Kernel and devices drivers, from programs that run on T-Monitor. Accordingly, programs that run on top of T-Monitor are mainly used for things like testing hardware and debugging, and they are not appropriate for regular applications.
Programs that Run on T-Kernel
These programs are the basic form of user applications that we run on T-Engine, and they are also the closest in form to the conventional embedded programs that used ITRON. User applications consists of one or multiple tasks, and we can use T-Kernel system calls from each task.
Programs that Run on Extensions
User applications that run on top of T-Kernel Extensions differ greatly from user applications that run on top of T-Kernel.
User applications on T-Kernel Standard Extension run in terms of units called processes, and they can utilize system calls that the extension provides rather than T-Kernel system calls. Among the system calls the extension provides, there are things such as process control, file control, and interprocess communication.
Likewise, user applications that run on T-Linux or T-Java also differ in other various ways.
In this paper, I shall explain programs that run on T-Kernel from the viewpoint of an introduction to T-Engine programming.
In explaining programs on T-Kernel, I will explain the characteristics of T-Kernel in a little more detail while comparing them with ITRON.
T-Kernel is divided into three parts: T-Kernel/OS (Operating System), T-Kernel/SM (System Manager), and T-Kernel/DS (Debugger Support). The functions of each are shown in Table 2.
|
|
|
| T-Kernel/OS | Task management functions |
| Synchronization and communication functions | |
| Memory management functions | |
| Exception/interrupt control functions | |
| Time management functions | |
| Subsystem management functions | |
| T-Kernel/SM | System memory management functions |
| Address space management functions | |
| Device management functions | |
| Interrupt management functions | |
| I/O port access support functions | |
| Power saving functions | |
| System configuration info management functions | |
| T-Kernel/DS | Kernel internal status reference functions |
| Execution trace functions | |
Among these, what forms the core of T-Kernel is T-Kernel/OS. Functions that correspond to ITRON are mainly under the charge of T-Kernel/OS. In the programming of applications that run on T-Kernel, what one first must understand is this T-Kernel/OS.
What T-Kernel/SM provides are extended functions in T-Kernel that did not exist in ITRON. In cases when we embed in a system middleware on T-Kernel, it is necessary for one to understand T-Kernel/SM.
What T-Kernel/DS provides are functions for development tools, such as debuggers. Accordingly, it is not necessary to be conscious of T-Kernel/DS in carrying out normal programming.
On that, I shall explain those functions that center on T-Kernel/OS.
In T-Kernel and ITRON, we call the resources that we make into the objects of operations kernel objects, or simply objects. Tasks and cyclic handlers, semaphores, mailboxes, etc., are all kernel objects. What we call creating programs on T-Kernel we could also call creating kernel objects.
In Table 3, I show a list of T-Kernel/OS kernel objects. These kernel objects are almost the same as the kernel objects of µITRON4.0.
|
|
|
| Task-related | Task |
| Synchronization and communication-related | Semaphore |
| Event flag | |
| Mailbox | |
| Extended synchronization and communication-related | Mutex |
| Message buffer | |
| Rendezvous port | |
| Memory pool management-related | Fixed-size memory pool |
| Variable-size memory pool | |
| Time management-related | Cyclic handler |
| Alarm handler | |
Let's take a look at the system calls that control kernel objects. As an example, I show in Table 4 a comparison of the event flag-related system calls of T-Kernel and µITRON4.0.
|
|
||
|
|
|
|
| Event flag generation |
|
|
| Event flag deletion |
|
|
| Event flag setting |
|
|
| Event flag clearing |
|
|
| Event flag waiting |
|
|
| Event flag status reference |
|
|
As one understands by glancing at them, the T-Kernel calls and the ITRON calls almost correspond with each other, and the names also become almost the same as the ITRON calls when we take away the tk_ prefix from the T-Kernel call name. Also, it would probably be acceptable to say that even the system call parameters are the same for basic functions such as event flag operations [1].
Based on as much as we have seen up to here, we can say that T-Kernel and ITRON are very much similar. However, if one asks if we can run an ITRON program at once if we change just the call names, things in fact don't go that simply. This is because in contrast to ITRON, where each type of resource is basically managed statically, dynamic management is carried out on T-Kernel. I shall explain this in the next section.
On T-Kernel, we dynamically manage each type of resource. This is important in order for T-Engine to function as a distribution platform for middleware, and it is a great difference with ITRON.
What one must first pay attention to in T-Engine programming is the fact that kernel object IDs are automatically assigned dynamically.
On both T-Kernel and ITRON, kernel objects are identified according to numerical values called IDs. What identifies a task is a task ID, and what identifies a semaphore is a semaphore ID.
On ITRON, normally, these IDs were determined statically at the time the program was created, and it was possible for the user to assign arbitrary values [2]. For example, in the case of task IDs, it was possible to determine at the time of programming that "the ID of Task A is 1, and the ID of Task B is 2."
On T-Kernel, object IDs are all automatically assigned dynamically at the time of program execution. For example, task IDs are assigned through T-Kernel internal processing at the time of task generation. Accordingly, the user cannot assign arbitrary IDs. Also, it becomes necessary to put down in variables inside programs IDs that are assigned by the kernel.
Memory management also is based on dynamic allocation in T-Kernel.
In ITRON, the user decided on the allocation of memory, and this was determined statically at the time the program was created. It was a situation in which the user created a so-called memory map. For example, in a case where one created a memory pool, the user had to allocate the memory region of that memory pool, and he/she had to transmit that to the ITRON system. In T-Kernel, when one creates a memory pool, if one only specifies the size of the memory pool, afterward when T-Kernel executes the program, it will allocate the memory region for you. It is the same also with the regions of message buffers, task stack regions, and so on.
Furthermore, T-Kernel is compatible with high-level memory management in which an MMU is used. Please take a look at the separately listed column "T-Kernel Memory Management" concerning this.
Lastly, I shall explain T-Kernel tasks.
User applications on T-Kernel are normally composed of one or multiple tasks. A task is generated with the tk_cre_tsk task generation call in T-Kernel.
|
|
|
|
|
|
| tskatr | Task attributes |
| task | Task startup address |
| itskpri | Priority level at task startup |
| stksz | Stack size |
| sstksz | System stack size |
| stkptr | Pointer to user stack |
| uatb | Task space page table |
| lsid | Logical space ID |
| resid | Resource ID |
| exinf | Extended information (user defined information) |
In Table 5, I show the parameters required in task generation. The properties and behavior of a generated task change according to the specifications of task attributes among the parameters. In Table 6, I show a list of task attributes that can be specified.
|
|
|
|
|
|
| TA_ASM | Task written with assembly language |
| TA_HLNG | Task written with high-level language |
| TA_SSTKSZ | Specifies system stack size |
| TA_USERSTACK | Specifies user stack size |
| TA_TASKSPACE | Specifies task space |
| TA_RESID | Specifies resource group to which a task belongs |
| TA_RNGn | Executes a task in execution level n |
| TA_COPn | Task uses the -nth coprocessor |
| TA_FPU | Task uses the floating point coprocessor |
The parameters that can be set are wide ranging, but the simplest task attributes can be set as follows:
ctsk.tskatr = TA_HLNG | TA_RNG0;
This task parameter means the following.
In a task with these attributes, the other parameters that must be specified are only the task startup address and priority level at the time of startup, plus the stack size. Also, a task with these attributes has properties that are very similar to an ITRON task up to now.
In running user applications, at least one must generate and start up a task. In the T-Engine kits, that function is provided on top of the development environment. Mr. Koichi Sato will explain the specifics of this while using the kit in the next section, "Put into Practice."
I have explained the basic matters of T-Engine programs up to here. Because the T-Engine system software possesses many functions, I am unable to give a full explanation of all of them here, but I believe that the preparations for writing simple programs have been completed.
In the following "Put into Practice," the reader will actually use the T-Engine development kit and run programs. In the development kit, the things necessary in T-Engine programming, from a development environment to sample programs, have been assembled. First, please put into practice practice makes perfect, and then try to run T-Engine in one way after another.
T-Kernel Memory ManagementA great feature of T-Kernel is that is has a memory management function that supports a Memory Management Unit (MMU). An MMU is hardware that realizes memory protection and virtual memory, and it has been made a mandatory function in standard T-Engine CPUs. In a case where one doesn't use the MMU, the program runs in physical address space in real memory that has actually been loaded on the board. ITRON programs run in this physical address space [1]. In a case when one uses MMU, the program runs in logical address space on top of virtual memory. Memory management in T-Kernel is mainly carried out with T-Kernel/SM, but the actual processing is carried out with an independent extension from the kernel. Accordingly, by modifying the extension, one can flexibly cope with different memory management mechanisms [2]. Here, I shall explain the memory management mechanism in accordance with the Standard Extension. T-Kernel Logical Address Space In T-Kernel, logical address space is divided into task space and shared space. Task space is memory space that only tasks belonging to that can access. Normally, a task belongs to one particular task space. It is permitted for multiple tasks to belong to one task space, but, conversely, it is not permitted for one task to belong to multiple task spaces. Shared space is memory space that can be accessed from all tasks. Shared space includes the region the system is using and the region that is shared among tasks. It is possible to access from a task the task space it belongs to and shared space. An example of this is shown in the figure. Task A in the figure can access only Task Space #1 and Shared Space. Task B and Task C can access only Task Space #2 and Shared Space. 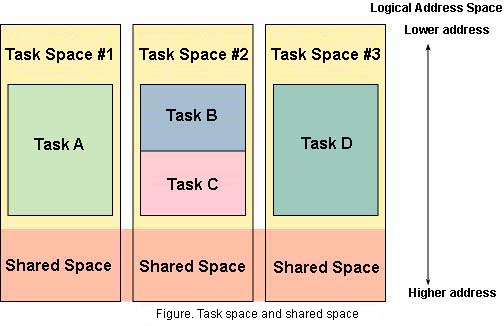 By setting up task space for each task, it is possible to prevent cases in which one task destroys the memory contents of another task. On the other hand, because it becomes impossible to share global variables among tasks, caution is required when switching over from existing ITRON programs. Memory Protection Levels In T-Kernel, protection levels are set in memory regions. There are four gradations to the protection levels, from level 0 to level 3, and the lower the number the higher the level. Also, an execution level corresponding to the protection level is set in tasks. A task with execution level N can access memory regions of protection level N and lower. For example, an execution level 2 task can access the memory of protection levels 2 and 3. Uses have been decided for the protection/execution levels, as shown in the table. Even in memory regions in shared space, if the protection/execution level is different, there cannot be access. By means of this, we can prevent such things as a user application destroying the system region. The protection/execution levels are realized using the functions of hardware, such as the CPU and MMU. Accordingly, the functions of the actual protection/execution levels depend on hardware. Many CPUs support two modes: a privileged mode and a user mode. In this case, levels 0 through 2 are assigned to the privileged mode, and level 3 to the user mode.
Virtual Memory Management With virtual memory, one can have address space in excess of real memory by swapping with regions in external memory on disks and the like. However, because processing such as accessing disks is generated with memory swapping, limits on operations and a drop in real-time performance occur. In T-Kernel, it is possible to specify memory regions into resident and non-resident. A region specified as resident memory will always exist in real memory, and there are no cases in which there will be swapping. ____________________ [1] Even with ITRON, there is the µITRON4.0/PX specification, which uses an MMU. However, this specification places emphasis on memory protection, and thus it is different from the memory management specification of T-Kernel. [2] Although the memory management mechanism is different, the T-Kernel interface does not change. By means of this, it is possible to maintain higher level program compatibility. |
||||||||||||
____________________
[1] It is not a situation in which they all completely match. Although T-Kernel is based on ITRON, because we did not stress compatibility with ITRON beyond necessity, there are cases in which functions have been improved or extended.
[2] With ITRON also, an ID dynamic assignment was incorporated from µITRON4.0. For example, when generating a task, we use the cre_tsk call as in the past in a case where we assign an ID statically, but in a case where we assign it dynamically, we use the acre_tsk call.
The above article on T-Engine programming appeared on pages 11-15 in Vol. 81 of TRONWARE . It was translated and loaded onto this Web page with the permission of Personal Media Corporation.
Copyright © 2003 Personal Media Corporation
Copyright © 2003 Sakamura Laboratory, University Museum, University of Tokyo