TRON Application Databus (TAD) is the standard for providing data compatibility among computers designed according to the TRON Architecture. This paper describes how character sets for multiple languages are handled in TAD.
The handling of multiple character sets in TAD is characterized by
In order to achieve these features, TAD incorporates:
Because of performance improvements in recent computers and the appearance of high-resolution, bit-mapped displays and laser printers, it has become technically possible to obtain computer output of the same level as typeset and photo-off set printed matter. This has led to a boom in so-called desktop publishing. On the other hand, as computerized publishing is popularized, demands are made by those wishing to handle various symbols, and texts in which multiple languages are mixed together. Both Xerox Corp.'s Star workstation and Apple Computer Inc.'s Macintosh II personal computer can cope with multiple languages, but they have unsatisfactory aspects. In particular, their handling of Japanese cannot be said to be satisfactory, which may be due to the fact that they were developed in the United States.
In the TRON Project [1], we will realize multilingual processing--which will become increasingly important in the future--in the Business TRON (BTRON) architecture [2] for workstations and personal computers. In particular, we have prescribed a TAD language environment in order to efficiently support Japanese, which is the most complicated among the languages to be processed. TAD is an abbreviation of TRON Application Data-bus, which is a set of rules for ensuring data compatibility in the TRON Architecture. The portion of TAD that is especially concerned with language is called the TAD language environment.
The TAD language environment is first of all aimed at the handling of documents mixed with multiple languages. When we consider the handling of documents mixed with multiple languages, it is not enough to simply assign codes to the characters of multiple languages. In English characters are written from left to right, but in Arabic the direction is from right to left. When it comes to changing lines, in Japanese it is all right in principle to break at any character, but in English it is considered poor form to break in the middle of a word. Therefore, when it comes to language, in addition to the differences in character shapes, there are language-specific rules, and these rules must be accommodated in order to carry out the editing of documents. Accordingly, the TRON rules for handling multiple languages are not simply called multilingual code, rather they are referred to as the TAD multilingual environment.
The second objective is the creation of an efficient code system. If a large number of languages is handled, the total number of characters could exceed 100,000. In such event, if the characters are encoded using a simplistic method, one character would be marked with three bytes. However, while this makes multilingual processing possible, a fair number of documents will be monolingual. Moreover, for languages such as English and French one byte is usually sufficient. In contrast to this, assigning a three-byte code is a waste no matter how much one says the cost of memory has dropped, and it is disadvantageous if one looks at it from the viewpoint of processing speed.
The third objective is to make application programs language independent so as to enable the international distribution of software. That is, the operating system has to become capable of handling multiple languages, and it has to be possible to create programs independent of language.
We propose the TAD language environment as a means of fulfilling these objectives.
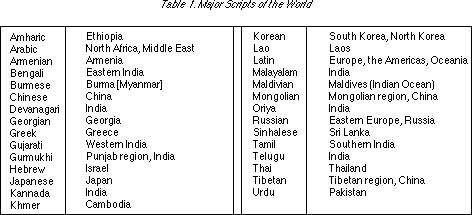
It is said that there are approximately 3,000-4,000 languages being used in the world at present. Among these, it is said there are roughly 200 key languages, and 95 percent of the world's population can be covered by 100 languages or less [3]. If we classify the characters of the key languages (e.g., languages in which newspapers are published), there are 29 types as shown in Table 1 [4]. For example, languages such as English, French, and German fall under Latin characters, since their basic alphabets use the same characters. In addition, depending on the language, there are also cases in which multiple character [types] are utilized together. In Japanese there are hiragana, katakana, and kanji [Chinese characters], and in Korean there are hangul and hanja [Chinese characters]. And then there is Esperanto, an artificial language whose character set falls under Latin characters.
In practical applications, it is enough to support 29 types of characters (these will be called scripts below to distinguish them from individual characters). However, in academic applications there is additionally a large number of characters. Researchers have constructed individual systems in order to handle foreign language and ancient characters on computers, but there are many cases in which unity has not been obtained among researchers, which is said to have become a great barrier to data exchange.
In order to also respond to demands such as these, in TRON, we will provide a system that will make it possible to handle all types of characters, and that will furthermore permit these to be mixed together in a single document. In addition, we have a basic policy of determining codes for all types of characters. Of course, for this purpose, we will need the cooperation of many people and an enormous amount of time, but it is a good method when we think in terms of data exchange via computer.
On present-day Japanese-language word processors and the like, using the gaiji [system external (i.e., user defined) character] concept, the user can employ characters and symbols [of his/her own creation] by assigning certain codes to them. However, if we adopt this method, it will become impossible to maintain compatibility when we exchange data. Even if, for example, we were to send character pattern data, it would become difficult to accommodate those data on printers with different resolutions and printing methods. Moreover, when we consider databases that are jointly utilized, searching for data would become chaotic. Accordingly, it becomes apparent that there is a need to assign codes to characters of a general-purpose nature.
I mentioned above that not just the differences in characters, but also the processing algorithms are influenced when we consider a system for processing multiple languages. In the above example, I pointed out the difference in the direction in which characters run. However, in addition to this, the following types of examples could also be mentioned.
(1) Character direction
As I have already mentioned, there are right to left, left to right, top to bottom, etc. If we include even ancient characters, then there are nine models [4]. In the complicated ones, the direction changes or becomes the mirror image when the line changes. The Japanese language also is rather complicated, being written both horizontally and vertically. When it is written horizontally it can be used from either the left or the right (this is of course an archaic way of writing, but we can still see examples [of writing from the right] at present, such as the characters written horizontally on cars and boats).
(2) Character changes due to positioning in a word
Typical examples are the characters of Arabic. Compared to their independent forms, the characters change shape into initial, medial, and final forms depending on their positions when they are run together [in words]. In German also, the small 's' of the German alphabet changes shape when it comes at the end of a word.
(3) Differences in the use of marks
In French quotations, there are marks called guillemets
. In German, these are reversed and used like this
. Moreover, there are also languages that use ' , ' for a decimal point and ' . ' for numerical units. These influence the processing of impermissible line breaks and the recognition of numerical values.
(4) Ligatures
Typefaces that combine two characters are used in printing from the viewpoint of aesthetics. For example, '
,
,
' are combinations of two characters. Although ' f ' and ' i ' are separate in spelling, there is a demand to display the character
(5) One character that appears as two
In Spanish, for example, CH is a single letter and the fourth letter of the alphabet. In dictionaries, it is not in the C heading, but in the CH heading that follows the C heading. It is all right to assign a code to CH as if it were one character, but it is necessary to show it as two characters when the spacing between characters is widened in printing.
(6) Processing of impermissible line breaks (kinsoku shori )
In principle, Japanese can break a line in the middle of a word, but in English breaking occurs between words. When breaking occurs in the middle of a word [in English], it has to be cut with a hyphen, and there are conditions as to the location of that break also.
Moreover, the kinsoku shori of Japanese-language word processors is very slipshod; the rules for printing (called kumihan [typesetting] rules) are more complicated.
(7) Input method
When we consider inputting certain languages from the keyboard, languages with large character sets--such as Chinese, Japanese, and Korean--become particular problems. In the case of Japanese, kana -kanji conversion and romaji -kana -kanji conversion are generally used, but various methods are under consideration. In languages with small character sets also, the input of characters with embellishmentssuch as 'ä'requires the striking of two keys.
When we look at the character types employed in certain languages, they can broadly be divided into two groups: those with several hundred [characters] and those with 5,000 or more [characters]. A large number of languages beginning with English fall under the former. Those that fall under the latter are languages that employ Chinese characters. Moreover, the hangul of Korean also comes under the latter since it has roughly 4,000 [commonly used syllabic blocks made up by combining the basic] characters [of the Korean alphabet].
The quantity of characters influences the length of code when processing by computer. Since they are normally handled using multiples of eight bits (which equal one byte), the code length is one byte for the former group and two bytes for the latter group.
If we make a detailed investigation of Chinese characters, there are approximately 50,000 characters listed in the Dai Kan -Wa jiten [5], which is the Chinese-Japanese dictionary that lists the most characters at present. Of course, among these are also included many characters that are used only in this Chinese-Japanese dictionary.
As to whether all Chinese characters are listed in Dai Kan -Wa jiten, there is a fair number of characters that do not appear in this dictionary, but which are characters that are actually in circulation. This is either because they are simplified or popularly used character types, or because the original character is not listed in the dictionary due to changes made to it during [the compiling of] the K'ang-hsi Dictionary. (The K'ang-hsi Dictionary, which lists 47,035 characters, was completed in 1716 after Ch'ing dynasty Emperor K'ang Hsi ordered it compiled. It serves as the basis for all present-day Chinese-Japanese character dictionaries.)
An example of the former is the character ![]() . This character
is in circulation as a simplified character for
. This character
is in circulation as a simplified character for ![]() ' rat ', but
it is not listed in Chinese-Japanese character dictionaries. An example
of the latter is
' rat ', but
it is not listed in Chinese-Japanese character dictionaries. An example
of the latter is ![]() . This character is the original
character for
. This character is the original
character for ![]() 'palace'; it was changed to
'palace'; it was changed to ![]() when the K'ang-hsi Dictionary was compiled. (The character form
when the K'ang-hsi Dictionary was compiled. (The character form ![]() . can be seen in ancient Shinto shrines [6].) Due to circumstances such
as these, the total number of Chinese characters exceeds 50,000 characters.
. can be seen in ancient Shinto shrines [6].) Due to circumstances such
as these, the total number of Chinese characters exceeds 50,000 characters.
Based on the objectives and background described thus far, the TAD language environment for supporting multilingual processing adopts the following system.
(1) Separation of algorithms
As I mentioned in section 2.2 above, in order to make application programs independent of languages, we must extract the parts that influence process-type algorithms and switch these language-specific algorithms in and out at the same time we switch languages. Language-specific algorithms can be classified into input algorithms and expression algorithms. Input algorithms are algorithms for fixing the character strings of a particular language from the keyboard or other input device; expression algorithms are algorithms that determine in what manner those input strings will be expressed as characters. Moreover, expression algorithms have occasion to be influenced by fonts. This is in order to cope with such things as connecting the space between two characters with a smooth curved lineas in cases when the font is a handwritten styleand word final characters that change as a result of font [characteristics]. These things change algorithms by responding to the [peculiarities of] fonts.
Furthermore, when processing documents on computers, it is necessary to perform sorting. Sorting algorithms are different for each language. In English, this is taken care of using a simple code order method, but it usually requires more complicated algorithms. For example, in German, 'ö' comes after 'o', but the word König 'king' comes before the word Konzert 'concert'. In other words, 'ö' has to first be sorted as 'o', and then there has to be sorting to distinguish between 'o' and 'ö'.
By grouping together and registering in the system the character set and these algorithmsexpression algorithms, sorting algorithms, and other language-dependent algorithmsit is possible to switch the environment at the same time the language is switched, thus realizing language independence for application programs. When we construct the system in this manner, application programs can be written without concern for languageonly message data has to be prepared in multiple languagesand it becomes possible to use them with any language.
(2) Language-specifier codes
In order to make application programs language independent, it is necessary to clearly carry out language switching. Accordingly, we insert language-specifier codes in [front of] character code strings, thus making clear which language the following character string is from.
(3) Separation of text description and character expression
Text description refers to how [a document] is described as text, and character expression refers to how the text description is expressed with characters when it is printed or displayed. In more concrete terms, in handling a ligature [such as
(4) Introduction of the script group
When we consider small character set languages such as English and German individually, the [number of] characters used is less than 256 characters, but the entire Latin script exceeds 256 characters. Accordingly, if we encode the Latin script in a simple-minded manner, we need two bytes. On the other hand, if we individually assign code to languages such as English and German in order to make one byte, inconveniences arise when we prepare the character set. In other words, if we collect all the characters of English, German, French, etc., that belong to the Latin script, the same characters will appear several times, and it will come about that we will have to prepare several instances of the same character.
In order to solve this problem neatly, in the TAD language environment, we think in terms of subsets that belong to the same script, and we introduce script groupings into which the collections of characters used in these languages are stored as one byte. These are called script groups [hereafter abbreviated simply as "groups"]. We define multiple groups so that we can include all the languages that belong to the same script. Certain languages we define so that they become partial groupings of one script or another. In addition, we prepare mapping functions from the group to the script, and we make the script a two-byte code.
When we do this, small character set languages can be expressed with one byte, and the character sets of certain scripts become the exact same groupings that are defined by the script. By also preparing in advance ligatures such as '
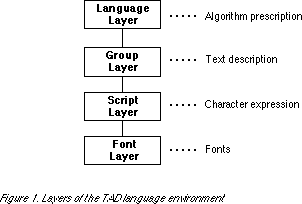
(5) Stratification of the language environment
As has been explained above, the TAD language environment is made up of four layers--the language, group, and script layers, to which the font layer is added.
The language layer is the layer at which a language such as English, German, Arabic, Chinese, or Japanese is recognized as an independent language. Algorithms for input, expression, sorting, and group mapping are incidental to [the] language [layer]. Since the language layer is a virtual layer, the code system consists of partial groupings of the group codes. In addition, because the group mapping algorithms are decided at the same time the groups are fixed, it could be said that they belong to the group layer. However, since language switching is indicated at the language layer, the group mapping algorithms are also attached to the language layer.
The group, as has already been explained, is the layer of text description. The language-specifier code specifies the group together with the language. This is because consideration was given to cases in which a certain language possesses multiple writing systems. For example, the Uighur language [spoken in China and the Commonwealth of Independent States] can be written with both the Latin and Russian scripts. For this reason, the language-specifier code consists of an encoding of a language and group combination. Group mapping algorithms from the group layer to the script layer are no problem with small character set groups, since a conversion table has at the most 256 entries. However, for large character set groups, conversion tables are huge. Accordingly, in order not to make conversion tables, we decided to arrange almost all portions so that they coincide without modification to the script layer code.
The script layer defines code for characters of identical character groupings (scripts). Moreover, this layer is the layer of character expression. Taking the Latin script, for example, this script has multiple Latin groups attached to it. Each of these Latin groups is expressed with a one-byte code, and all of them include characters such as 'A, B, C'. The Latin script code, on the other hand, is a two-byte code, and there is only one 'A, B, C' to which the 'A, B, C' of each group is mapped.
The same character can exist among the characters of different scripts. For example, there is an 'A' is the Latin, Greek, and Russian scripts. As characters they resemble each other, but since their code systems are different, we distinguished these [from one another].
Since the script layer is the layer of character expression, it also includes characters needed in printing, such as ligatures, which are not needed in text description. The characters included in a script are the collection of characters that must be created when a font is made for the first time. If a font provider designs and furnishes a font as script units, it makes it possible to completely display the language of the groups attached to that script.
The font layer prescribes font codes. Fonts are collections of characters of different designs that can be identified as the same characters. In concrete terms, Mincho, Soocho, Kyookasho, Naaru, Gosikku, and Times Roman are some fonts. Even when there is a difference just in thickness, [the collection of characters] is considered to be one font. As for the code system, all the characters of a script have correspondences to a certain font, but it is acceptable to prepare only those parts that are necessary for an implementation.
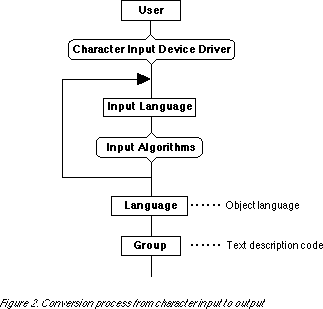
The application of input algorithms in the TAD language environment is an important part of the language independence of application programs. Fig. 2 shows the the process of a user inputting text from a character input device (e.g., a keyboard) and how it becomes text description at the group level. When the user inputs something from the character input device, the Character Input Device Driver (CIDD) converts it into the input language.
Taking as an example the input of Japanese from a keyboard using kana -kanji conversion, the CIDD converts the output location code (the code that corresponds to the key locations without regard to language) into kana code. This kana code is an expression of the input language layer. Next, the input language is converted into the expression of the language layer using the input algorithms. In this case, this is the conversion of kana into mixed kana and kanji. The input algorithms are not applied in just one step, rather they are permitted to be applied in several steps. In romaji -kana -kanji conversion, alphabetic strings are received from the CIDD and converted into into kana with the input algorithms of the first step, and then converted into mixed kana and kanji with the input algorithms of the second step, thus completing the text description.
Moreover, if we replace the CIDD part of this scheme with the driver for another type of input device, then it becomes possible to handle voice and handwritten character recognition input.
The TRON code system has one-byte and two-byte character codes. By inserting language-specifier codes at the boundaries, one-byte and two-byte character codes can be mixed together in a single text.
Control codes, character codes, language-specifier codes, TRON escape codes, and special codes are assigned in the TRON one-byte character code. Fig. 3 gives an outline of this.

The control codes are 34 characters running from hexadecimal (00) through (20), plus (7E), and they are used for basically the same meanings as the ASCII control codes. Among these, the following characters possess meanings for TRON text description.
Other characters are utilized as communication control characters, but these do not possess meaning in text description. (20) is a separator. The separator indicates word and phrase divisions as opposed to a blank, (A0). The handling of the separator differs according to language, but in English it is dealt with as a space. In other words, it is used as a gap when lines are broken, and it displays a variable-length space used for proportional spacing.
The character codes cover 220 characters running from (21) through (7E), (80) through (9F), (A0), and (A1) through (FD). (A0) is a blank and is handled as a blank character that possesses a given fixed width. In the case of English, this is called a "required space." A required space is the same as a letter of the alphabet, and it is treated as a letter in a word. However, it cannot come together with punctuation for breaking a line.
The language-specifier code (FE) is used to specify the switching of the language and group for the codes running successively from (21) through (7E) and (80) through (FD). Moreover, it can be expanded into multiple bytes in the following manner.
(FE) [(FE)] . . (xx)
on the condition that (xx) is either (21) through (7E) or (80) through (FD), and [Z] . . is either void or a repetition of [Z]
Accordingly, the number of language specifiers that can be expressed with two bytes is 220, which increases by another 220 for each byte that is added.
TRON special code (FF) is recognized as a TRON special code when the code that follows it runs from (21) through (7E). TRON special codes will be used with TRON Application Control-flow Language (TACL), and they will be employed as special codes that will be embedded in text.
TRON escape (FF) is utilized as TRON escape when the code that follows it runs from (80) through (FE). TRON escape is used for punctuation in text and graphic segment data, and punctuation symbols for specification fusen embedded in text. Data follows after the punctuation symbol. The punctuation symbols are usually two bytes, but they can be expanded into multiple bytes [as shown below].
(FF) [(FE)] . . (xx)
on the condition that (xx) runs from either (21) through (7E) or from (80) through (FD)
The number of TRON escape sequences that can be expressed with two bytes is 126, which can be increased by 220 for each byte added.
The TRON two-byte code is apportioned into four character zones (A, B, C, and D), language specifier codes, TRON escape codes, and special codes. Fig. 4 gives an outline of this. Moreover, control codes (including tab, paragraph break, line break, and separator) are mixed as one-byte character codes inside two-byte character codes.
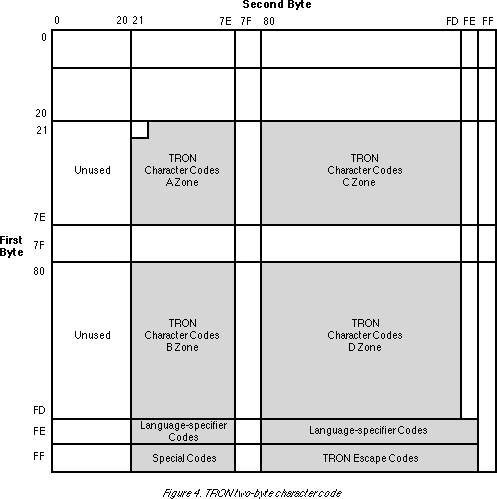
The TRON character codes are:
which make a total of 48,400 characters. (21) (21) is a blank and is handled as a blank space that possesses a given fixed width. The language-specifier codes, TRON special codes, and TRON escape sequences are the same as the one-byte character codes.
Language-specifier codes are codes that determine the language and group. We are currently in the process of assigning these codes; some examples of language and group combinations are given in Table 2.
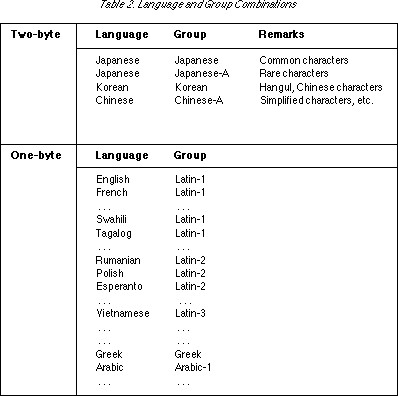
The numerals and letters of the alphabet that appear behind the group codes have the following meanings: the numeral indicates that a group goes across multiple code sets, and that it can be specified with any one of the code sets when a specific language is designated; the letters of the alphabet, on the other hand, indicate cases where one language requires multiple character sets.
Japanese-language TRON code is a two-byte code. The Japanese group is a code set for ordinary use that includes the characters of JIS X0208, some additional kanji, and various symbols. Japanese-A group, on the other hand, takes in very rare characters that are not included in the Japanese group.
The A zone of the Japanese group corresponds with JIS X0208. However, because there are deficiencies in the Latin characters of JIS X0208, and in order to maintain correspondence with the Latin group of TRON code, we do not use alphabetic characters that correspond with those of JIS X0208, rather we use B zone. In B zone, we have gathered together high-frequency use characters from among the characters that are deficient in JIS X0208. Among these are included symbols and a portion of the characters of some other groups, in addition to some kanji. In C and D zones, characters of lower frequency than those of A or B zones are gathered together. Characters other than these are included in Japanese-A group.
The characters of Latin-1 group that are included in the Japanese group are as far as possible [considered as] those of the Japanese group, and not those of Latin-1 group. In other words, these characters are treated as certain symbols used with Japanese characters. Accordingly, in order to mix Japanese and English in the true sense, it is necessary to switch in and out of the Latin-1 group, which is a one-byte character code type. However, the way in which the alphabet is normally used in Japanese is almost always brief. Since it is typically used for things such as enumerating points in a preface with A, B, C, switching from one language to another would be inappropriate. For this reason, characters of Latin-1 group are assigned to the Japanese group.
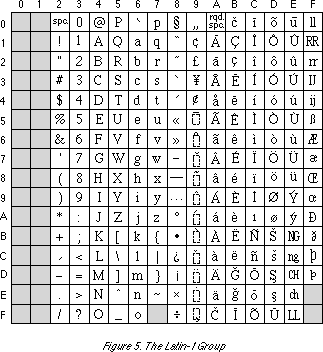
Fig. 5 shows an example of Latin character code assignment in which we
have gathered the characters of important languages that belong to the Latin
script. (00) through (7F) are the same as ASCII code. In the chart, there
are expressions such as ' ![]() ', which means the character
consists of the embellishment on the right is added to the character on
the left. In other words, in this case, it means the character 'ä'.
Latin-1 group can at the least support the languages in Table 3.
', which means the character
consists of the embellishment on the right is added to the character on
the left. In other words, in this case, it means the character 'ä'.
Latin-1 group can at the least support the languages in Table 3.

In this paper, I have described the TAD language environment with particular concern for multilingual processing in TAD. The main objectives of the TAD language environment are: (1) the handling of text in which multiple languages are mixed, (2) an efficient code system, and (3) making application programs language independent to enable them to be distributed internationally. In order to achieve these objectives, the TAD language environment adopts a system in which (1) the switching of languages is clearly executed through the introduction of language-specifier codes, (2) the efficiency of the code system is raised through the use of one-byte and two-byte codes, and (3) groups of algorithms and parameterssuch as typesetting and input algorithms for language and fontsare bundled together so that language environments can be switched when languages are switched.
Systems for handling multiple languages have appeared in the Xerox Star workstation and Apple Macintosh II personal computer. The Star workstation employs a code for multilingual handling, and it uses an object-oriented approach to enable the distribution of programs. This system has some outstanding aspects, but there are problems in that it is a closed architecture and the object-oriented approach is not very efficient on present-day hardware. In order to maintain continuity with the past, the Macintosh II uses font switching to switch scripts, while at the same time switching the incidental algorithms. Accordingly, when modifying all the fonts in a mixed, multilingual document, it is necessary for the user to instruct modifications for each of the respective languages. Moreover, because there is no concept of language, there is the possibility that the editing and display algorithms will not be able to handle all the differences among the languages.
The TAD language environment is able to provide a more ideal environment for multilingual handling by incorporating multilingual handling functions in the system and stratifying them into language, group, script, and font layers. Accordingly, application programs can easily be made language independent, and software can be distributed [internationally] without much effort. As a result, multilingual handling will facilitate the use of TRON by a wide range of people, and play a role in information and culture exchange.
Finally, I would like to extend my thanks to various volunteers as well as the members of the BTRON Technical Committee of the TRON Association who generously cooperated in gathering and arranging characters. It is my sincere desire that they will continue to extend their cooperation in the future.
[1] Sakamura, Ken. "The TRON Project." IEEE Micro, April 1987, pp. 8-14.
[2] Sakamura, Ken. "BTRON: The Business-oriented Operating System." IEEE Micro, April 1987, pp. 53-65.
[3] Katzner, Kenneth. The Languages of the World. Rev. ed. London: Routledge & Kegan Paul, 1986.
[4] Nakanishi, Akira. Writing Systems of the World. Tokyo: Charles E. Tuttle Co., 1980.
[5] Morohashi, Tetsuji. Dai Kan-Wa jiten [Unabridged Chinese-Japanese dictionary]. Rev. ed., 13 vols. Tokyo: Taishukan Shoten, 1986.
[6] Emori, Kenji. Kaisetsu jitai jiten [Dictionary of character forms with explanatory comments]. Tokyo: Sanseido, 1986.
The contents of the above paper have appeared both in Japanese and English in several different publications, most recently on pages 49-57 in Vol. 50 of TRONWARE. This translation was taken from a TRON Association publication, Collected Papers on BTRON Multilingual Processing with an Appended BTRON1 Introductionary Operation Manual, which was published in June 1992.
Copyright © 1992 TRON Association
Copyright © 1998 Sakamura Laboratory, University Museum, University of Tokyo