
The general release of T-Kernel/Standard Extension (hereafter T-Kernel/SE), which expands the functions of T-Kernel, has at last approached. In this article, I will explain in outline form exactly what type of software T-Kernel/SE is.
T-Kernel is a real-time operating system for new generation embedded systems. It is succeeding µITRON technology, which has been used in the world of embedded systems for many years and has many achievements, and it has been newly designed so that it ought to cope with embedded systems that are becoming larger in scale and higher in functions as the days go by.
The functions demanded in an embedded operating system have become so great that they do not compare with the age in which µITRON was designed and popularized. Both a file system and network functions, which at one time were only used in a portion of systems, are now becoming commonplace. In order to manage software that has become large in scale, it has come about that both high level memory management and resource management functions are demanded. However, just embedding these functions into T-Kernel and moving forward will lead to bloating of the operating system itself, and it will also come about that it will lose its light weight and high responsiveness, which were advantages of µITRON. Embedded system products are extremely wide in breadth, and while the highly functional ones demand functions such as a file system and networking, there are also many ones that demand the light systems of yesteryear.
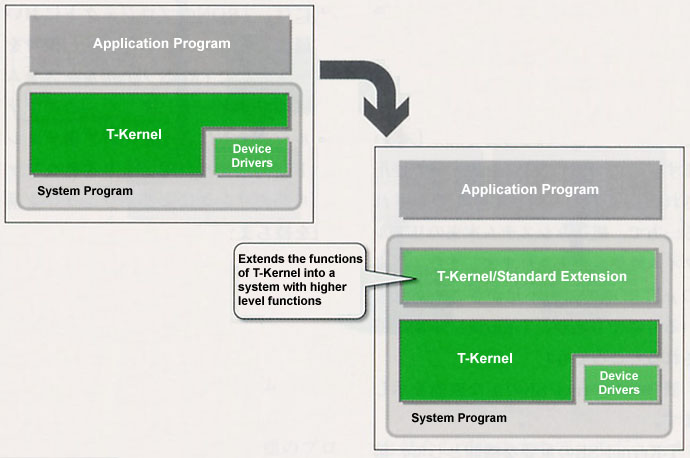
In order to respond to these demands, in T-Kernel, we have decided to implement only the basic functions of a real-time operating system in the main body of the kernel, and to provide extend functions, such as a file system, in the form of T-Kernel extensions. This makes it possible to use T-Kernel as a microkernel, and, by combining it with extensions, we can also grasp it as something for constructing highly functional systems (Fig. 1).
 |
|
|
In T-Kernel, there are functions, called subsystems, which support modules for extending its own operating system functions. Normally, an extension is realized by utilizing the functions of these subsystems. In actuality, the substance of an extension will probably be constructed from several subsystems.
In addition, as one can also understand from the above scheme, the switching of T-Kernel extensions is possible. If we utilize a different extension, we can build a separate highly functional system on top of T-Kernel. In terms of the future, something like utilizing optimum extensions based on systems created from among various extensions may even become possible.
Among these extensions, we call those that are being developed by the T-Engine Forum as standard extensions, native extensions. T-Kernel/SE, which I will introduce in this article, forms one of these native extensions.
Also, we call that which each vendor is independently developing a ported extension. For example, T-Linux, which MontaVista announced, is a ported extension.
 |
|
|
T-Kernel/SE, as the name Standard Extension implies, was designed and developed as the standard extension of T-Kernel (Fig. 2).
As for its target, we assume fields where high-level functions are demanded even among embedded systems, such as information appliances and next generation cell-phones. In these fields, while on the one hand functions close to information-type operating systems used in personal computers and servers are demanded, the original real-time performance of embedded systems is also demanded. Moreover, these are also fields in which it has been murmured that the existing µITRON has insufficient power, and thus they are also areas where T-Kernel/SE is hoped for.
In Table 1, I show the main functions of T-Kernel/SE.
|
|
|
| Memory management function | File management |
| Process/task management function | Device management functions |
| Message function among processes | Event management functions |
| Global name function | Clock management function |
| Synchronization/communication function among tasks | System management |
| Shared library function | |
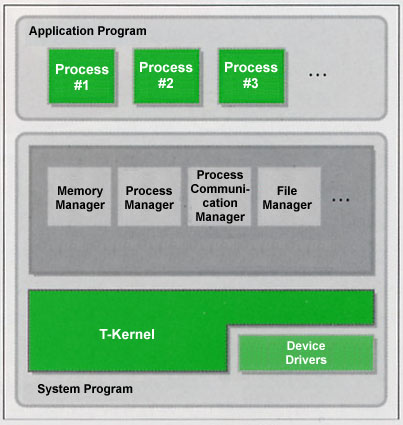
As for the important functions of T-Kernel/SE, first of all, there are memory and resource management functions that can cope with the development of large-scale programs. An application program that runs on top of T-Kernel/SE is managed in units called processes. The individual processes run on top of independent logical address spaces. In addition, various resources also are managed in units of processes. Even in T-Kernel itself, there are functions through which we carry out execution in different logical address spaces for each task using an MMU, and through which we manage resources as resource groups. However, these functions in the standalone T-Kernel are quite basic ones, and they are functionally insufficient to employ as is from a user application. T-Kernel/SE has realized high-level functions called process managers on the basis of these basic functions of T-Kernel. Incidental to process management, there are such things as a message function among processes, a global name function, and a synchronization and communication function among tasks. I would like to give a little more detailed explanation concerning processes in the following section.
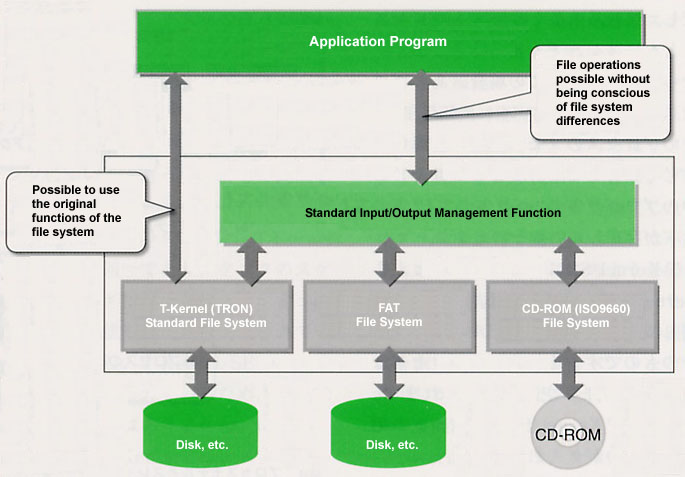
Second, as an important function, there is the file system. In the file system, we have supported as standard the TRON file system based on real objects/virtual objects, which was researched and developed in the TRON Project. This file system does not possess the common hierarchical directory structure, rather it possesses a more flexible network structure based on links among files.
However, in order to maintain compatibility with other systems, it has also been made compatible with FAT file systems and a CD-ROM file system (ISO9660) that are utilized a lot in embedded systems. Moreover, it is made up with a scheme in which the addition of those other file systems also can easily take place. Also, it possesses a standard input/output management function so that one can control files in an environment where multiple file systems have been mixed without doing one's utmost to be aware of their respective differences.
Furthermore, the use of a file system in T-Kernel/SE is not mandatory. Among embedded systems there also exist products that do not possess an external memory device. Accordingly, T-Kernel/SE has been conceived of in a manner in which, for example, it is possible to run a diskless system on a ROM base (Fig. 3).
 |
|
|
Outside of this, in regard to device control, there are such things as device functions that carry out direct control of devices, and event management functions that handle asynchronous information from devices in a unified manner. The event management functions are important functions for the purpose of building user interfaces on top of T-Kernel/SE. However, user interfaces are not included in the scope that corresponds to T-Kernel/SE.
A network function also is not included in the T-Kernel/SE release on this occasion. A TCP/IP protocol stack that runs on top of T-Kernel/SE is under development, and it is scheduled to be released later.
An application program that runs on top of T-Kernel/SE consists of processes, and the processes furthermore consist of tasks.
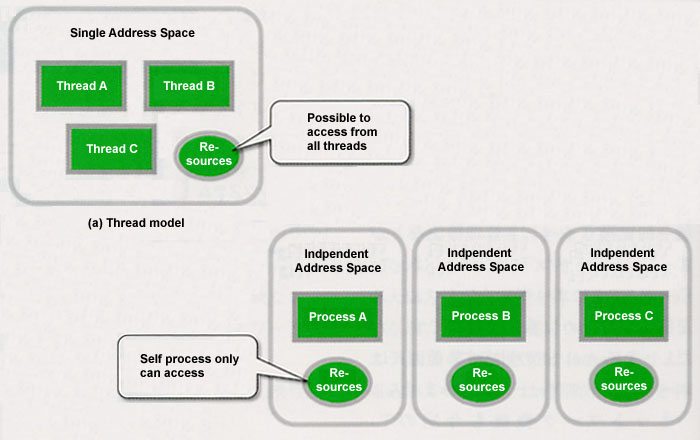
Before I give an explanation about processes and tasks in T-Kernel/SE, I will briefly explain about the process model and the thread model. These terms are not T-Kernel technical terms, but rather they are used in general in expressing schemes for the parallel execution of programs. What we call processes and threads are both units of programs that are executed in parallel. The big difference between the two is that in comparison to resources, including such things as memory, being independent for each process in the process model, in the thread model, these are shared among the threads.
In concrete terms, a process normally runs in independent memory space. The memory spaces of other processes are protected at a lower level, and it is not possible to access them arbitrarily. As for the exchange of information among processes, there is nothing outside of using the communication function among processes that the operating system provides. What is mainly used in information-type operating systems, such as Linux, is this process model.
In contrast to this, threads run in common memory space. Accordingly, information can be shared freely to a certain extent among threads. What has been frequently used in traditional embedded systems is this thread model. One could say that a µITRON task is equivalent to a thread (Fig. 4).
 |
|
|
The process model and the thread model have their respective advantages and disadvantages. The advantage of the process model lies in the high independence of the process. Because a process is coupled with another process only by using functions that the operating system provides, its independence as a module becomes very high. Also, because the memory space is different, even if a certain process runs wild, damage to other processes can be held to a minimum. As for the disadvantage of the process model, we can raise the fact that the overhead time at the time of process switching and communication among process becomes great in comparison to the thread model.
The advantages and disadvantages of the thread model form as is the flip side of the advantages and disadvantages of the process model. With threads, switching is rapid in comparison to processes, and the sharing of information is simple, but all the more, it is easy for the connections among the threads to become strong, and they also easily receive influence from each other.
That the thread model has mainly been used in embedded systems and the process model in information-type systems up to now is something that is based on the above characteristics. However, it has come about that both processes and threads can be used even in a lot of information-type operating systems. In this case, multiple threads exist inside a certain process, and they run by sharing the memory space and resources of that process. In other words, one could say that threads exist as program execution units inside a process.
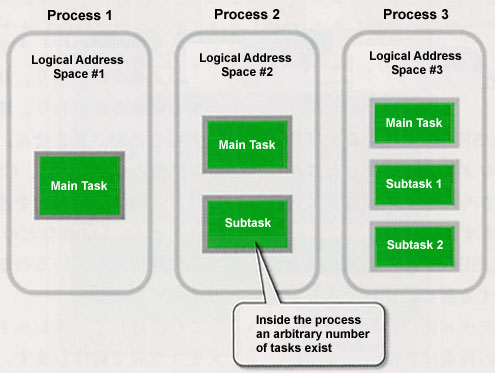
Returning the discussion to T-Kernel/SE, a process in T-Kernel/SE is the very process of the process model that I have explained up to here. The respective processes are executed in independent memory space. And then, the thing that corresponds to a thread in T-Kernel/SE is a task.
In T-Kernel/SE, a task is a program execution unit inside a process, and inside one process, one or more tasks will surely exist. When we create a process, a task called the main task is automatically created. In this state, it is probably all right to think of the process and its main task as the same. In other words, what we call executing that process comes down to executing the main task. When we employ the service calls of T-Kernel/SE, we can further create tasks inside the process. Tasks that are created afterward are called subtasks, and they share memory space and resources with the tasks inside the same process. One can think of this as equivalent to the model in which multiple threads exist inside a process in the information-type operating systems previously mentioned (Fig. 5).
 |
|
|
In the previous section, I have explained processes and tasks from the point of view of the common process and thread model. Here, I would like to go on to look at the process and task of T-Kernel/SE from the point of view of T-Kernel.
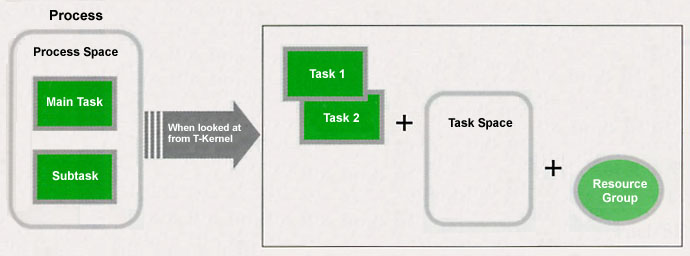
A T-Kernel/SE task is basically the same thing as a T-Kernel task. In both T-Kernel and T-Kernel/SE, the basic unit in executing programs is to the last a task, and scheduling is carried out with regard to tasks. Then, if one asks what's a process, we could take it as a unit of resource management, including memory space.
As a function of standalone T-Kernel, there is a function that assigns task memory space and a resource group to individual tasks. In T-Kernel/SE, by utilizing this function, we create task memory space and a resource group for each process, and we assign them to the tasks that belong to that process.
In other words, if we look at a T-Kernel/SE process from T-Kernel, it can be taken as one task space and one resource group, plus one or multiple tasks that belong to them (Fig. 6).
 |
|
|
As I have already mentioned, in T-Kernel/SE, scheduling is carried out in units of tasks, and processes are not related to this. The priority level set in the process becomes the priority level of the main task. In a case where only one task exists in a process, there is nothing to be particularly conscious of, but with scheduling in a case where multiple tasks exist in a process, there is a need to be conscious of the fact that this is carried out in units of tasks.
For example, let's assume that the priority level of process A is 5 and the priority level of process B is 10. In a case where it is possible for both processes to be executed, the first thing to be executed will be the main task of process A. However, in a case where a priority level 3 subtask exists in Process B, this subtask will be executed first. That which decides the scheduling comes down to the priority level of each task.
I will explain in a little more detail about T-Kernel/SE task scheduling.
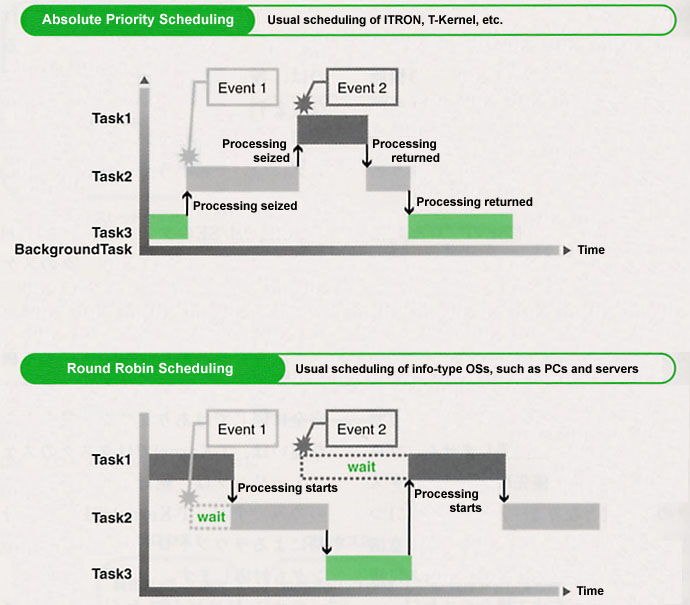
A T-Kernel/SE task is basically the same as that of T-Kernel, and task scheduling has been realized on the base of the T-Kernel scheduling function. However, because the extension of the function has also been carried out through T-Kernel/SE, the both of these are not completely the same. The biggest difference is that in T-Kernel the scheduling of tasks is something based only on absolute priority; in T-Kernel/SE, the system is also compatibility with round robin scheduling based on time division.
Round robin scheduling divides the CPU time, allots it to tasks, and then goes on to execute each task in order. It is generally used in information-type operating systems, and one could say that its affinity with the process model is good on the point that it handles tasks (processes) that run in parallel as independent things. However, there is a problem in responsiveness to events that occur asynchronously, and thus one could also say that it is unsuitable for embedded systems, which call for real-time control.
On the one hand, scheduling based on absolute priorities is the general rule in real-time operating systems in embedded systems. While this is outstanding in real-time performance, we could say that it is not suitable in running in parallel comparatively independent programs in the manner of higher level applications. Actually, in this type of case, even with operating systems that carry out scheduling based on absolutely priorities, assigning the same priority level to tasks, and conducting round robin utilizing time events and so on is normal (Fig. 7).
 |
|
|
In T-Kernel/SE, by means of the priority level assigned to a task, we divide into the three groups of the Absolute Priority Group, the Round Robin Group 1, and the Round Robin Group 2. The priority level among the groups becomes the Absolute Priority Level Group > the Round Robin Group 1 > the Round Robin Group 2, and corresponding scheduling takes place inside the respective priority level group (Fig. 8).
 |
|
|
Accordingly, in T-Kernel/SE, it becomes possible to assign tasks that carry out processing with high real-time performance to the Absolute Priority Group, and, conversely, applications and the like, which don't demand real-time performance, to the round robin groups.
Up to here, I have explained that T-Kernel/SE, while maintaining T-Kernel functions and real-time performance as is, will be extended up to the point where it rivals information-type operating systems. Even in highly functional large-scale embedded fields, where it has been difficult to cope by means of standalone T-Kernel or µITRON, coping will become possible by means of using T-Kernel/SE.
One more thing that can be raised here as an important feature of T-Kernel/SE is that it has been developed with much importance attached to affinity and compatibility with T-Kernel. This is also a big difference between systems that use T-Kernel/SE and hybrid-type operating systems that I will explain from here.
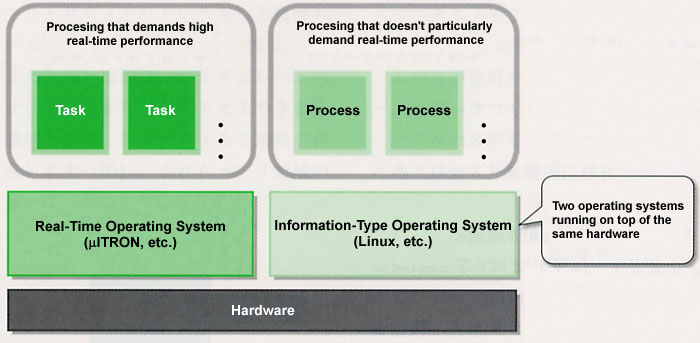
What we call a hybrid-type embedded system operating system is something in which by combining together and using an information-type operating system and a real-time operating system, we utilize the good parts of both and compensate for their shortcomings. In frequent examples, there are things such as hybrids of Linux and µITRON. This is a case where designers use µITRON in the parts where real-time performance is necessary, and they use Linux in parts such as the higher level applications where real-time performance is not so important.
As for this kind of hybrid-type operating system, in a certain aspect, one could say that it is practical. One could also surely say that it's the most suitable in a case such as when you have used existing Linux software, but real-time control is not possible with just Linux (Fig. 9).
 |
|
|
The hybrid operating system approach also has parts that are similar to T-Kernel and T-Kernel/SE. However, the big difference is the point that with a hybrid operating system you are trying to run two operating systems that are completely different. In both operating systems, with both the APIs and the program models, and everything up to the smallest operating methods are different. For example, everything from data-type definitions up to minute matters, such as the error code system, are different things. In building up one system, knowledge of both operating systems becomes necessary, and thus there is the possibility that one will force an increase to the burdens of program development. Moreover, when looked at over the long term, the demerit that one will have to continually maintain two operating systems is also not small.
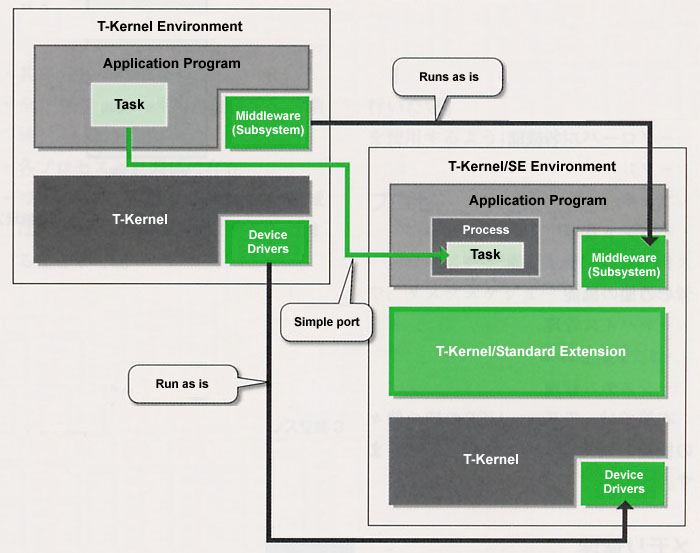
On this point, T-Kernel/SE has been created on top of the same system as a pure functional extension of T-Kernel, and it has been designed in a manner that T-Kernel/SE and T-Kernel preserve compatibility to the utmost in such areas as the synchronization and communication function among tasks and the device management function. Accordingly, porting a task created on top of the standalone T-Kernel to T-Kernel/SE is simple. Furthermore, because T-Kernel/SE runs on top of T-Kernel to begin with, for device drivers and subsystems, the same ones as those for T-Kernel can be used. It will also be possible to use a lot of middleware as is.
In this manner, with T-Kernel and T-Kernel/SE, the sharing of software resources and know-how is possible. Support with scalability, in which comparatively small-scale embedded systems are T-Kernel only and in which we use T-Kernel/SE with systems that are large in scale, also becomes possible (Fig. 10).
 |
|
|
Evaluation of a vendor's version of T-Kernel/SE has been carried out in the T-Engine Forum for close to two years. During this time, numerous tests, which have included actual adaptation in manufactured products, have been carried out, and those results have been reflected and improvements have been made. And now, at last, the general release has drawn near.
The general release of T-Kernel/SE is planned as something based on T-Kernel that is open, and that anyone can freely use. To both those who have continued to use T-Engine and T-Kernel up to now, and also to those have felt dissatisfaction in terms of the functions in the standalone T-Kernel and µITRON, please, by all means, take this opportunity to try out T-Kernel/SE.
The above article on T-Kernel appeared on pages 17-23 in Vol. 99 of TRONWARE . It was translated and loaded onto this Web page with the permission of Personal Media Corporation.
Copyright © 2006 Personal Media Corporation
Copyright © 2006 Sakamura Laboratory, University Museum, University of Tokyo