
"World Character Input" is a system through which we can input from the keyboard [1] all the characters that can be utilized on Cho Kanji.
In Cho Kanji we have provided many language modules as standard equipment, but it is possible to customize these or newly create language modules.
On this occasion, I would like to try actually creating from scratch a World Character Input module [2].
I would now like to try to construct a language module that
outputs "![]() "
[a Chinese character pronounced 'a'] when we type "a"
from the keyboard.
"
[a Chinese character pronounced 'a'] when we type "a"
from the keyboard.
Procedure [3]
If Kihon 1 is displayed in the lower right of the system message panel, then it is properly registered. In this state, change the kana-to-kanji conversion mode to "alphanumeric [eisuu]." This will be displayed [in the system message panel] as "Ra" (in the case of Roman letter input) or "a" (in the case of kana input) [Fig. 1].
After registering in World Character Input, input "a"
from the keyboard in a manuscript form, etc. The character "![]() " will be output on the screen
[Fig. 2].
" will be output on the screen
[Fig. 2].

Explanation of the Script
Let's take a look at what is actually happening in the script we input in (3) of the Procedure.
The correspondence table we draw up of character strings input from the keyboard and the character strings that correspond to them becomes the basis of language modules created in this manner.
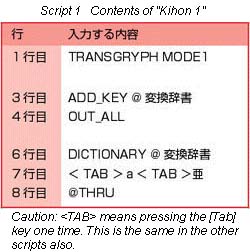
In Kihon 1, we input an alphabetic character stamped on the keyboard and output a corresponding Chinese character, but what should we do in a case when the input character string in the dictionary definition is not stamped on the keyboard?
For example, when we take a look at a dictionary definition part from the Korean language module, a character that is not on the keyboard is defined [Script 2].

Figure 3 is the Korean key arrangement; "![]() "
[the Korean script character for 'm'] is allotted to the spot
for "a" on the keyboard.
"
[the Korean script character for 'm'] is allotted to the spot
for "a" on the keyboard.

With World Character Input, in this type of case, by using the SET_KEY script command, it is possible for us to make a character that is not stamped on the keyboard the input character.
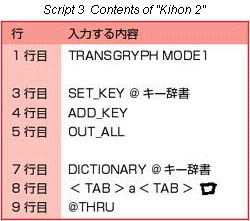
Here, as "Kihon 2," we shall create a language
module that modifies and fixes the input character from "a"
to "![]() " when we type
"a" on the keyboard [Script 3].
" when we type
"a" on the keyboard [Script 3].
Register this Kihon 2 in World Character Input, and
then input "a" from the keyboard using a manuscript
form or the like. The character "![]() "
is output on the screen [Fig. 4].
"
is output on the screen [Fig. 4].

Explanation of the Script
In this manner, by using SET_KEY, it is possible to make a character not stamped on the keyboard the input character.
This is made up in a form in which Kihon 1 and Kihon 2 are combined.
Here, for Kihon 3, we will create a language module
that when we input "a" on the keyboard will convert
the input character to "![]() ,"
and will output and fix "
,"
and will output and fix "![]() "
for the the input character "
"
for the the input character "![]() "
[Script 4].
"
[Script 4].

Register Kihon 3 in World Character Input, and then
input "a" from the keyboard with a manuscript form or
the like. The character "![]() "
is output on the screen [Fig. 5].
"
is output on the screen [Fig. 5].

Explanation of the Script
Because it is in the same form as Kihon 1 and Kihon 2, I shall omit an explanation.
When "a" is input on the keyboard, inside the script,
the input character is converted into "![]() ,"
and "
,"
and "![]() " is output
and fixed for the input character "
" is output
and fixed for the input character "![]() ,"
but the screen operation results become the same as Kihon
1.
,"
but the screen operation results become the same as Kihon
1.
In the Kihon scripts up to this point, the input character is automatically converted and fixed, but with World Character Input it is possible to for us to carry out an operation of the type in which when we input a character and press the "Henkan [Conversion]" key, the character is converted for the first time and the corresponding character output, and then when we press the right [Ctrl] key ([O] key), we fix it.
Here, as Kihon 4, we will create a language module in
which when we type "a" on the keyboard and push the
conversion key, we output "![]() "
[Script 5].
"
[Script 5].

Input "a" from the keyboard. On the screen, "a" is displayed as is, and it is in unfixed status [Fig. 6].

Here, we push the Henkan key. On the screen, "a"
is converted into "![]() "
and displayed [Fig. 7].
"
and displayed [Fig. 7].

In this status, we push the the right [Ctrl] key ([O] key).
The character "![]() "
becomes fixed [Fig. 8].
"
becomes fixed [Fig. 8].

Explanation of the Script
In this script, conditions based on the input keys carried out different operations.
I believe that you can understand that the same operation method as the conventional operation method in which we convert characters by means of the "Henkan" key is possible also in World Character Input also, and that the script too is not complicated.
In the Kihon scripts up to here, I have not described the operations of all the keys on the keyboard in order to make the explanations easy to understand. In actual language modules, what sort of operation takes place when one presses each key is described.
However, in cases where basic operations are carried out with World Character Input, I believe that just making additions to and/or modifying the contents of the dictionary based on the script of Kihon 4 will prove useful in in various types of applications.
On the basis of the World Character Input scripts explained on the occasion, I will be glad if they serve as a reference when creating new language modules.
____________________
[1] This article is based on the 106-key Japanese-language keyboard as the keyboard that will be used. In a case when the reader will be using another keyboard, please make a timely rereading.
[2] For an explanation of World Character Input and the like, please refer to the "World Character Input" column under "Accessories," which is under "Basic Items" in the "User Manual" utility.
[3] There is no explanation of the procedure from Kihon 2 onwards, so please perform the operations by referring to the procedure for Kihon 1.
[Translator's Note] The translator personally went to Personal Media Corporation and confirmed that each of the scripts described in this article actually work. According to what he was told there, these scripts are not written in the MicroScript visual programming language, rather they are scripts with statements that are unique to the World Character Input utility, which interprets them. Therefore, the spaces between the lines of code are acceptable, and are, in fact, how language modules for the World Character Input utility are written. Line numbers are not used. On the other hand, the "<TAB>" portions of the above scripts must left out if the scripts are to be properly interpreted. In other words, do not input
"<TAB>a<TAB>![]() "
"
rather input
If you are uncertain as to how to set up the input/output character columns, open an existing World Character Input module in the Cho Kanji 4 operating system and use that for reference.
B-right is a registered trademark of Personal Media Corporation.
The above article on World Character Input appeared on pages 60-64 in Vol. 77 of TRONWARE . It was translated and loaded onto this Web page with the permission of Personal Media Corporation.
Copyright © 2002 Personal Media Corporation
Copyright © 2002 Sakamura Laboratory, University Museum, University of Tokyo